

Community
25 AI benchmarks: examples of AI models evaluation

contents
With new large language models (LLMs) constantly being released, how do you know which is better?
When a new AI model is presented, it is typically accompanied by key information about the model, including its evaluation results on various AI benchmarks (see the GPT-4o model card as an example). These benchmarks indicate how well each model handles specific tasks, from reasoning to coding to tool use.
In this blog, we’ll explore AI benchmarks and why we need them. We’ll also provide examples of widely used AI benchmarks for different LLM capabilities, such as reasoning and language understanding, conversation abilities, coding, information retrieval, and tool use.
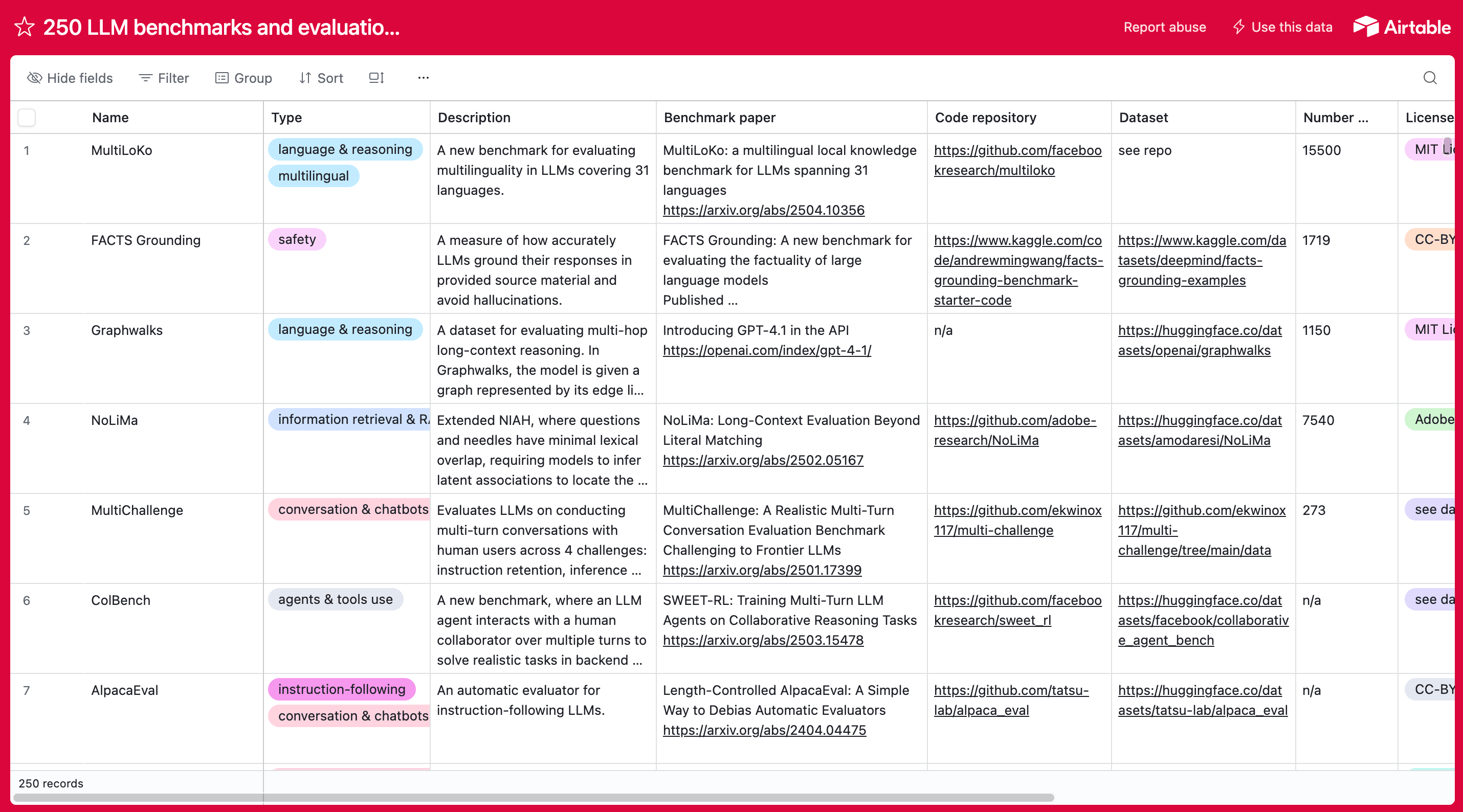
Want more examples of AI benchmarks? We put together a database of 250+ LLM benchmarks and datasets you can use to evaluate the performance of language models.
What are AI benchmarks, and how do they work
AI benchmarks are standardized tests or datasets used to measure and compare the performance of AI models on specific tasks. They serve as a common reference point to understand how well a specific model performs, where it struggles, and how it compares to others. Think of them as tests students take to be graded on a particular subject.
AI benchmarks typically include three main components:
- Test dataset
- Evaluation method or script
- Leaderboard
Dataset. A dataset is a set of inputs and (optionally) expected outputs to test model performance. Inputs are tasks a model can complete, like solving math problems, writing code, answering questions, or translating text. For language models, a dataset usually consists of questions or sentences; for vision models, labeled images or videos; and for multimodal models, combinations of text, images, or structured data.
Outputs are “ground truth” answers to compare against and evaluate the quality of a model’s responses. For example, these can be correct labels or answers to the test questions.
Evaluation metrics. Each benchmark includes evaluation rules to quantify how the model outputs transform into performance scores. Different evaluation methods can be used depending on the task. Sometimes, this is a simple matching process: the model returns multiple-choice answers, and the total accuracy (share of correct answers) is taken into account.
In code generation tasks, benchmarks can include programmatic evaluation, for example, to assess how well LLM-generated code passes unit tests in a specific code base.
Some benchmarks use more sophisticated methods, like LLM-as-a-judge, to evaluate the quality of responses using a predefined evaluation prompt. For example, the MT-bench uses LLM evaluators to assess the bias and verbosity of models in multi-turn conversations.
Leaderboards are ranking systems that show how different AI models perform on standardized benchmarks. They are great for tracking how different models compare and encouraging transparency and competition.
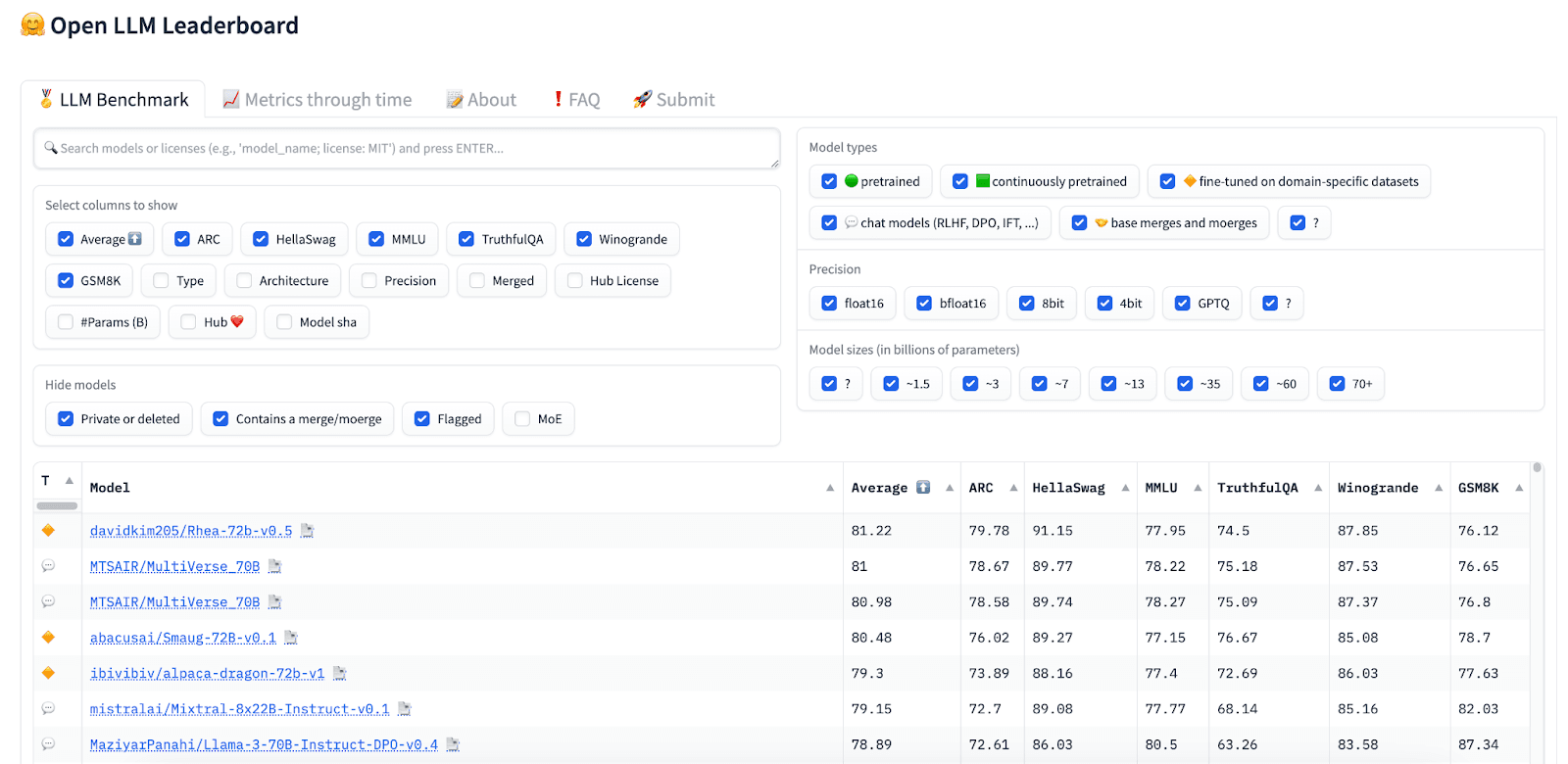
Many benchmarks maintain their own leaderboards (e.g., the SuperGLUE leaderboard or the MMLU leaderboard). Public leaderboards also exist – they aggregate scores from various popular benchmarks (e.g., the Open LLM leaderboard for open-source models from Hugging Face).
AI benchmarks examples
There are dozens of AI benchmarks out there. Below, we highlight some of the commonly used benchmarks you can use to evaluate LLM capabilities in various domains, including reasoning, conversation, coding, tool use, and more. We briefly describe and link each example to research papers, public datasets, and leaderboards.
AI benchmarks for reasoning and language understanding
[fs-toc-omit]HellaSwag
HellaSwag is a benchmark for evaluating commonsense natural language inference. It challenges models to choose the most plausible ending to a given sentence. The answer options include adversarial, machine-generated distractors – plausible but incorrect choices that demand nuanced reasoning to dismiss.
Paper: HellaSwag: Can a Machine Really Finish Your Sentence? by Zellers et al. (2019)
Assets: HellaSwag dataset, HellaSwag leaderboard

[fs-toc-omit]MMLU-Pro
MMLU-Pro (Massive Multitask Language Understanding Pro) is an enhanced dataset that extends the MMLU benchmark. It was introduced to overcome the original benchmark's limitations, as top LLMs started getting near-perfect scores, making it difficult to tell their capabilities apart.
It consists of 12,000 challenging questions from various domains and sources. Each task has a choice set of 10 options, making it harder to “guess” the correct answer.
Paper: MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark by Wang et al. (2024)
Assets: MMLU-Pro dataset, MMLU-Pro leaderboard
[fs-toc-omit]SuperGLUE
SuperGLUE is an advanced benchmark developed as a tougher successor to the original GLUE, which LLMs had surpassed. It assesses how effectively LLMs perform across diverse real-world language tasks, such as contextual understanding, inference, and question answering. Each task is scored using its own evaluation metric to measure the model’s overall language understanding ability.
Paper: SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems by Wang et al. (2019)
Assets: SuperGLUE dataset, SuperGLUE leaderboard

[fs-toc-omit]BIG-Bench
The Beyond the Imitation Game Benchmark (BIG-bench) is a collaborative benchmark to assess language models' reasoning and extrapolation abilities. It includes 204 tasks contributed by 450 authors from 132 institutions, covering various subjects such as linguistics, mathematics, biology, physics, and more. These tasks go beyond simple pattern recognition to determine whether LLMs can demonstrate human-like reasoning and understanding.
Paper: Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models by Srivastava et al. (2022)
Assets: BIG-bench dataset, SuperGLUE leaderboard
[fs-toc-omit]Humanity's Last Exam (HLE)
Humanity's Last Exam (HLE) is a multi-modal benchmark designed to challenge LLMs toward expert-level human reasoning and knowledge. It features 2,500 questions from various fields, including mathematics, the humanities, and natural sciences. The questions were filtered to exclude those that could be easily answered through web searches or memorized prompts.
Paper: Humanity's Last Exam by Phan et al. (2025)
Assets: HLE dataset, HLE leaderboard

AI benchmarks for coding
[fs-toc-omit]SWE-bench
SWE-bench (Software Engineering Benchmark) evaluates how well LLMs can resolve real-world software issues taken from GitHub. It comprises over 2,200 issues and their corresponding pull requests drawn from 12 popular Python repositories. The benchmark challenges models to generate code patches that fix the identified problems using the provided codebase and issue description.
Paper: SWE-bench: Can Language Models Resolve Real-World GitHub Issues? by Jimenez et al. (2023)
Assets: SWE-bench dataset, SWE-bench leaderboard

[fs-toc-omit]Mostly Basic Programming Problems (MBPP)
Mostly Basic Programming Problems (MBPP) assesses the ability of language models to write short Python programs from natural language instructions. It contains 974 beginner-level tasks that cover fundamental programming concepts such as list manipulation, string processing, loops, conditionals, and basic algorithms. Each task includes a prompt, a reference solution, and test cases to verify the model’s output.
Paper: Program Synthesis with Large Language Models by Austin et al. (2021)
Assets: MBPP dataset

[fs-toc-omit]HumanEval
HumanEval evaluates an LLM’s ability to generate high-quality code. It measures how well a model understands programming tasks and produces syntactically correct and functionally accurate code.
The benchmark contains 164 programming problems, each paired with unit tests that automatically verify whether the generated code meets the expected outcomes. A model’s output is considered correct only if it passes all test cases for the task.
Paper: Evaluating Large Language Models Trained on Code by Chen et al. (2021)
Assets: HumanEval dataset

[fs-toc-omit]Repobench
RepoBench was introduced to evaluate code auto-completion in realistic, multi-file software repositories. It consists of three related tasks: retrieval, code completion, and the combination of the first two.
RepoBench-R (Retrieval) evaluates how well the model can find relevant code snippets in other files that help with code completion.
RepoBench-C (Code Completion) tests how accurately the model can predict the following line of code, using both in-file and cross-file context.
RepoBench-P (Pipeline) is a combined task: the model must first retrieve appropriate cross-file snippets and then use them and the in-file context to generate the next line of code. This simulates a full auto-completion workflow.
Paper: RepoBench: Benchmarking Repository-Level Code Auto-Completion Systems by Liu et al. (2023)
Datasets: RepoBench-R, RepoBench-C, RepoBench-P

[fs-toc-omit]DS-1000
DS-1000 is a code generation benchmark for solving data science-oriented programming problems. It includes 1000 tasks drawn from StackOverflow and reflecting realistic scenarios.
The tasks cover seven commonly used Python libraries, including NumPy, Pandas, Scikit-Learn, and TensorFlow.
The challenges mirror real-world tasks, from data manipulation to building a simple neural network to visualizing data.
Paper: DS-1000: A Natural and Reliable Benchmark for Data Science Code Generation by Lai et al. (2022)
Assets: DS-1000 dataset, DS-1000 leaderboard

AI benchmarks for chatbots
[fs-toc-omit]MT-bench
MT-Bench evaluates the performance of LLMs in multi-turn dialogues. Unlike single-turn assessments, MT-Bench focuses on how well models maintain context and exhibit reasoning abilities across multiple conversational exchanges.
The benchmark includes tasks from eight categories: writing, roleplay, extraction, reasoning, math, coding, STEM, and social sciences. The evaluation consists of two turns: first, the model responds to an open-ended question, and then a follow-up question is presented in the second turn. To automate scoring, MT-Bench uses LLM-as-a-judge, which rates responses from 1 to 10.
Paper: Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena by Zheng et al. (2023)
Assets: MT-bench dataset

[fs-toc-omit]Chatbot Arena
Chatbot Arena takes a distinctive approach to evaluating LLMs by comparing their conversational skills in a competitive setting. In this “arena,” chatbots powered by anonymous language models are paired and interact with users simultaneously. Each model responds in turn to the same user prompt, and the user votes for whichever response they prefer. After voting, the identities of the models are revealed.
Paper: Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference by Chiang et al. (2024)
Assets: Chatbot Arena dataset, Chatbot Arena leaderboard
[fs-toc-omit]WildChat
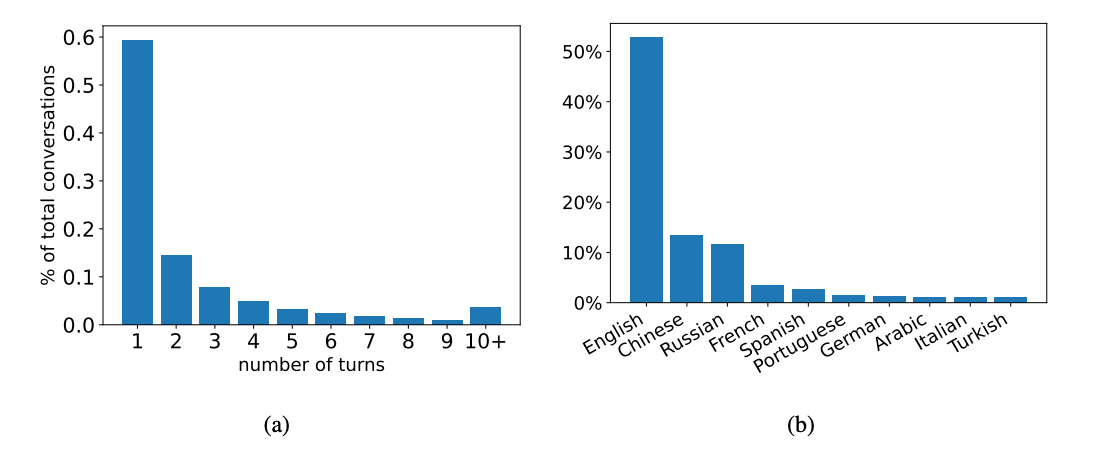
WildChat evaluates LLMs' conversation abilities using real-world, multi-turn conversations. It draws on over 1 million anonymized user-chatbot interactions comprising more than 2.5 million turns.
WildChat supports multiple languages and provides demographic and behavioral metadata, enabling nuanced model performance analysis across regions and user types. The dataset captures a wide range of user intents, from factual questions to creative requests.
Paper: WildChat: 1M ChatGPT Interaction Logs in the Wild by Zhao et al. (2024)
Assets: WildChat dataset
[fs-toc-omit]MultiChallenge
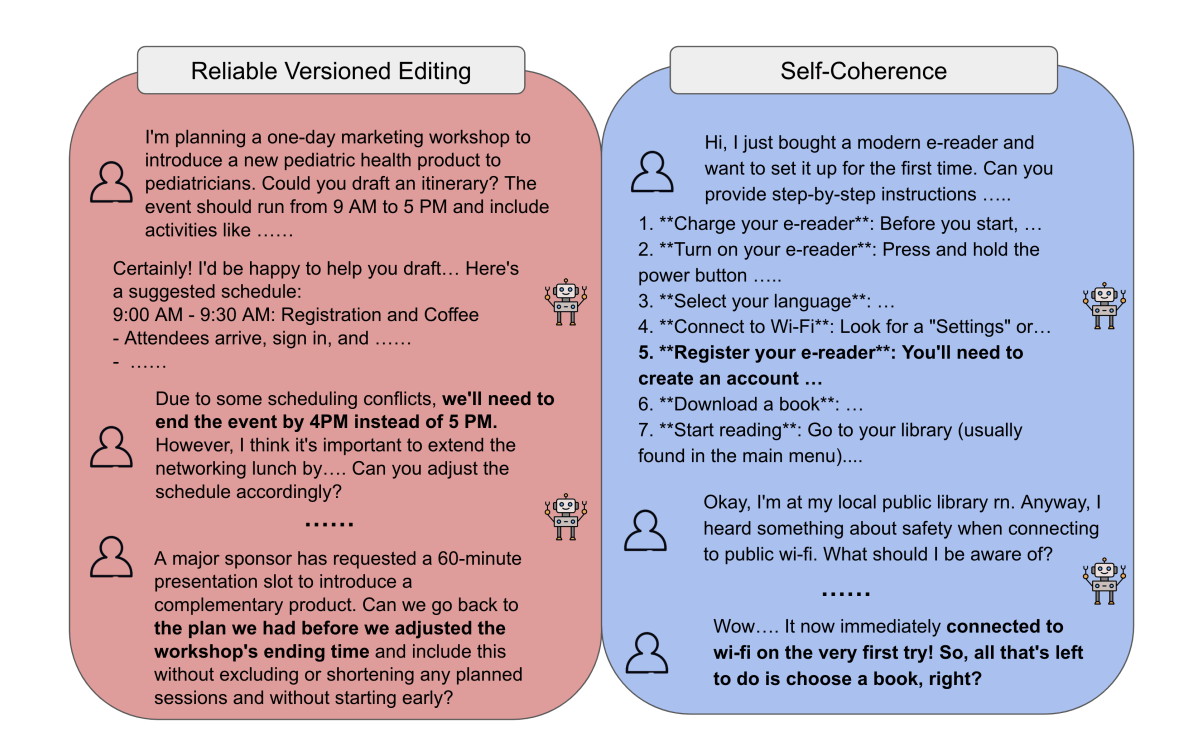
MultiChallenge is another benchmark that evaluates LLMs in multi-turn conversations with human users. It aims to assess models on four key challenges:
- Instruction Retention reflects the model's ability to remember and follow instructions across multiple conversational turns.
- Inference Memory indicates the model's capacity to recall and utilize information provided earlier in the conversation.
- Reliable Version Editing demonstrates the model's proficiency in updating its responses based on new information or corrections.
- Self-Coherence shows the model's consistency and logical flow in its responses throughout the conversation.
Like MT-bench, MultiChallenge uses LLM-as-judge to automate the evaluation process.
Paper: MultiChallenge: A Realistic Multi-Turn Conversation Evaluation Benchmark Challenging to Frontier LLMs by Sirdeshmukh et al. (2025)
Assets: MultiChallenge dataset
[fs-toc-omit]SPC (Synthetic-Persona-Chat Dataset)
The Synthetic-Persona-Chat (SPC) dataset is a persona-based conversational dataset designed to improve and scale human-like dialogue grounded in user personas. It builds on the original Persona-Chat dataset by generating synthetic conversations among the original persona pairs and between newly created synthetic personas.
SPC aims to help language models produce more consistent, persona-aware responses, supporting research in dialogue systems that maintain character, style, or user-specific traits. The dataset contains roughly 20,000 persona-grounded dialogues, making it a significant resource for training and evaluating conversational AI.
Paper: Faithful Persona-based Conversational Dataset Generation with Large Language Models by Jandaghi et al. (2023)
Assets: SPC dataset

AI benchmarks for AI agents and tool use
[fs-toc-omit]Berkeley Function-Calling Leaderboard
The Berkeley Function-Calling Leaderboard assesses LLMs' ability to call external functions, APIs, or tools in response to user queries. BFCL assesses models across several dimensions: function relevance detection, syntax correctness, executable accuracy, irrelevance detection, and multi-turn reasoning.
It includes over 2000 question-answer pairs in several languages, including Python, Java, JavaScript, SQL, and REST APIs.
Paper: Berkeley Function-Calling Leaderboard by Yan et al. (2024)
Dataset: BFCL dataset

[fs-toc-omit]WebArena
WebArena is a benchmark paired with a self-hosted environment for testing autonomous agents on web-based tasks. It simulates realistic scenarios across four domains: e-commerce, social forums, collaborative code development, and content management.
The benchmark measures functional correctness, considering a task successful if the agent achieves the intended goal, regardless of the specific steps taken. It includes 812 templated tasks and their variations, such as navigating e-commerce sites, moderating forums, editing code repositories, and interacting with content management systems.
Paper: WebArena: A Realistic Web Environment for Building Autonomous Agents by Zhou et al. (2023)
Dataset: WebArena dataset

[fs-toc-omit]MINT
MINT assesses LLMs' ability to solve tasks through multi-turn interactions involving tool usage and natural language feedback. It utilizes a diverse set of existing datasets, including HumanEval, MBPP, GSM8K, HotpotQA, MATH, MMLU, and TheoremQA, to create a compact subset of tasks. The MINT dataset covers three task categories: reasoning and question answering, code generation, and decision-making.
The benchmark also provides an evaluation framework where LLMs can access tools by executing Python code and receive natural language feedback simulated by GPT-4.
Paper: MINT: Evaluating LLMs in Multi-turn Interaction with Tools and Language Feedback by Wang et al. (2023)
Dataset: MINT dataset

[fs-toc-omit]Webshop
WebShop is a simulated e-commerce environment for evaluating LLM-powered agents on web-shopping tasks. It features 1.18 million real-world products and 12,087 crowd-sourced instructions, such as "I’m looking for an x-large, red-colored women's faux fur lined winter warm jacket coat, and a price lower than 70.00 dollars."
To succeed, agents must navigate multiple types of webpages, perform searches, apply filters, and complete purchases, mirroring realistic e-commerce interactions.
Paper: WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents by Yao et al. (2023)
Dataset: Webshop dataset

[fs-toc-omit]MetaTool
MetaTool tests whether an LLM can decide when and which tools to use in real-world scenarios. Its core dataset, ToolE, contains over 21,000 user queries with single- and multi-tool scenarios labeled with correct tool assignments. MetaTool assesses models across four subtasks: selecting the best tool among similar options, choosing tools based on context, identifying tools with potential reliability issues, and handling multi-tool usage.
Paper: MetaTool Benchmark for Large Language Models: Deciding Whether to Use Tools and Which to Use by Huang et al. (2023)
Dataset: MetaTool dataset

AI benchmarks for RAG
[fs-toc-omit]NeedleInAHaystack (NIAH)
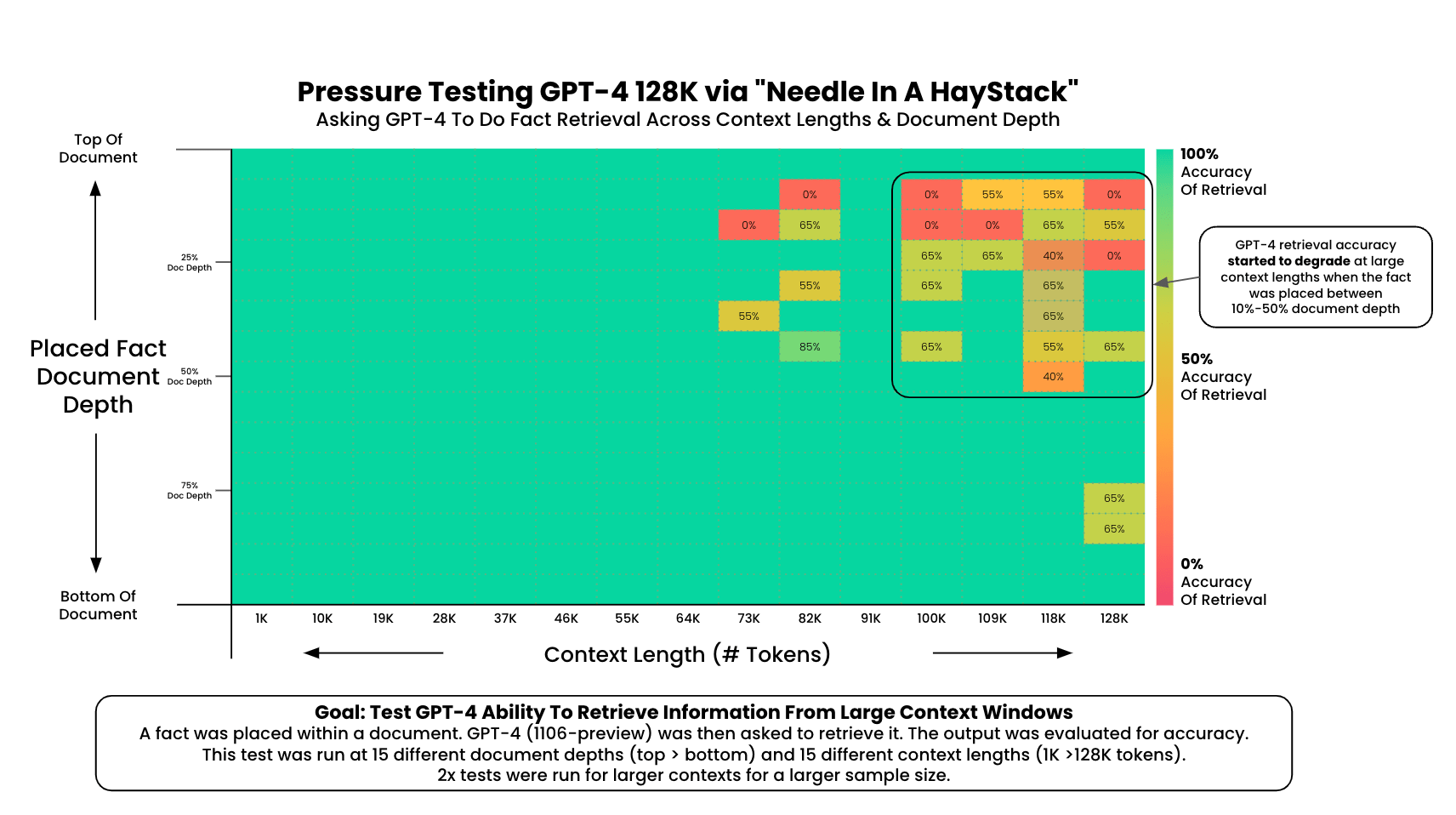
The Needle-in-a-Haystack (NIAH) test evaluates how well LLMs can locate specific information ("needle") within extensive text ("haystack"). In a typical NIAH setup, a random fact is embedded within a lengthy text, and the model retrieves this fact. To measure its retrieval accuracy, the test examines the model's performance across various document depths and context lengths.
Recently, multimodal versions of NIAH, such as MM-NIAH, were introduced. They assess models' capabilities to process and retrieve information from long multimodal documents, including text and images.
Video explainer: Needle In A Haystack by Greg Kamradt
Test repo: Needle In A Haystack on GitHub
[fs-toc-omit]RULER
RULER builds on the original NeedleInAHaystack (NIAH) test by introducing variations in both the number and types of “needles” (target information) within extensive contexts. It evaluates LLM performance across four task categories: retrieval, multi-hop reasoning, aggregation, and question answering.
As a synthetic benchmark, RULER automatically generates evaluation examples according to configurable parameters such as sequence length and task complexity.
Paper: RULER: What's the Real Context Size of Your Long-Context Language Models? by Hsieh et al. (2024)
Dataset: RULER dataset

[fs-toc-omit]FRAMES
FRAMES (Factuality, Retrieval, And reasoning MEasurement Set) is a dataset for evaluating RAG systems on factuality, retrieval accuracy, and reasoning. It contains over 800 multi-hop questions requiring models to integrate information from multiple sources to answer accurately. Some questions also include numerical comparisons to test the model's ability to handle quantitative data.
Paper: Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation by Krishna et al. (2024)
Dataset: FRAMES dataset

[fs-toc-omit]BeIR
BeIR (Benchmarking Information Retrieval) is a comprehensive benchmark for evaluating the performance of information retrieval (IR) models. It unifies 18 datasets, covering domains such as Wikipedia, scientific papers, news, and social media. The benchmark supports various retrieval scenarios – from passage retrieval to document retrieval to question-answering.
Paper: BeIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models by Thakur et al. (2021)
Dataset: BeIR dataset

[fs-toc-omit]CRAG
The Comprehensive RAG Benchmark (CRAG) is a factual question-answering benchmark introduced by Meta AI to evaluate the performance of RAG systems.
It comprises over 4400 question-answer pairs and mock APIs that simulate web and Knowledge Graph (KG) searches. It spans five domains and eight question types, from simple facts to complex reasoning tasks to questions with false assumptions. The benchmark also considers factors such as entity popularity and temporal dynamics, with answers varying from seconds to years.
Paper: CRAG – Comprehensive RAG Benchmark by Yang et al. (2024)
Dataset: CRAG dataset

Limitations of AI benchmarks
AI benchmarks are valuable tools for evaluating model performance. They offer a standardized way to compare language models and track progress over time. However, AI benchmarks have limitations.
AI benchmarks can age fast. As models improve and hit near-perfect scores, benchmarks lose their value when comparing performance. A test is no longer useful if everyone always scores an A! This phenomenon is known as benchmark saturation.
Another challenge is data contamination. It occurs when benchmark test data leaks into a model’s training set, undermining the benchmark’s integrity. Essentially, the model can accidentally “memorize” the answers instead of genuinely solving the task. This can lead to false conclusions about model capabilities.
AI benchmarks may not reflect real-world scenarios. Most benchmarks evaluate models on narrow tasks, like question answering or text classification. In the real world, however, AI systems face ambiguous instructions, shifting contexts, and multi-turn interactions. A model that aces a benchmark might still struggle when dealing with messy user inputs or domain-specific edge cases.
AI benchmarks are not suited for evaluating AI-based applications. Benchmarks only measure a model’s raw capabilities, e.g., reasoning or the ability to produce functional code. LLM-based applications – the systems built on top of those models – are more complex. They include prompts, business logic, user context, and safety constraints. Evaluation of AI-based apps needs to be tailored to the use case and solution architecture.
Create a benchmark for your AI app
While AI benchmarks are great for comparing models, they fall short when evaluating LLM-based applications.
Whether building a chatbot or an AI coding assistant, you need a custom benchmark and a test dataset that reflects your use case. It should include real inputs and examples of expected behavior, capturing the key scenarios and edge cases unique to your application. You’ll also need task-specific evaluations – for instance, LLM judges aligned with your criteria and preferences.
That’s why we built Evidently. Our open-source library with over 30 million downloads makes it easy to test and evaluate LLM-powered applications, from chatbots to complex systems like RAG and AI agents.
We also provide Evidently Cloud, a no-code workspace for teams to collaborate on AI quality, testing, and monitoring, and run complex evaluation workflows. You can generate synthetic data, create evaluation scenarios, run adversarial tests, and track performance – all in one place.
Ready to test and evaluate your AI app? Sign up for free or schedule a demo to see Evidently Cloud in action. We're here to help you build with confidence!


.svg)


Get started with Evidently

