


contents
AI hallucinations are among the most demanding challenges in GenAI development. They’re not just trivia mistakes: hallucinations can lead to wrong medical advice, fabricated citations, or even brand-damaging customer responses.
In this blog, we’ll explore eight real-life AI hallucinations examples across different use cases – from chatbots to search assistants. Learning from these failures is the first step toward building reliable, trustworthy AI systems that perform safely in the real world.
What are AI hallucinations and why do they happen?
AI hallucinations occur when a large language model – like GPT, Claude, or Gemini – confidently produces false, misleading, or fabricated information. AI hallucinations come in different forms: from giving factually incorrect responses to making up a citation that doesn’t exist to inventing product features or even nonexistent people.
AI hallucinations stem from how generative models work. Here are some factors that cause LLMs to hallucinate:
Prediction, not knowledge. LLMs don’t actually “know” facts. Instead, they predict the next word based on patterns learned from massive text data. If the training data is sparse or inconsistent, the model may “fill in the gaps” with something plausible but untrue.
Lack of grounding in reality. Most models generate outputs based on publicly available data they were trained on, rather than a particular knowledge base. Without grounding LLM outputs in trusted data sources, you can’t always rely on them for precise information.
Training data issues. If the data used to train the model contained outdated information or fabricated web content, those errors can show up in generation.
Prompt ambiguity or pressure. When asked something unclear or when the model “feels pressure” to answer (e.g., “give me five reasons…” even if only two exist), it prefers to produce something plausible rather than admit uncertainty.

AI hallucinations examples
AI applications powered by LLMs – from chatbots to coding assistants – also “inherit” the ability to generate outputs that look plausible but are factually incorrect or unfaithful to their source. While some failures become light-hearted memes, others bring real consequences to the companies behind these apps – from lost lawsuits and six-figure compensation payments to tarnished brand reputations and frustrated customers.
In this blog, we will explore seven real-world AI hallucinations examples that occurred in the wild.
AI fabrications in a government contract report
A report provided by Deloitte to Australian government, was found to contain multiple fabricated citations and phantom footnotes. As a result, Deloitte will refund part of a ~$300,000 government contract.
After a University of Sydney academic flagged multiple errors in the report and urged the company to investigate, Deloitte acknowledged it had used a generative AI tool to fill “traceability and documentation gaps” in its analysis.
The revised version of the report strips more than a dozen bogus references and footnotes. Though officials claim the report’s substantive recommendations are unchanged, the incident undermines trust in consultancy practice, especially when a paid expert report relies partially on flawed AI-generated content.
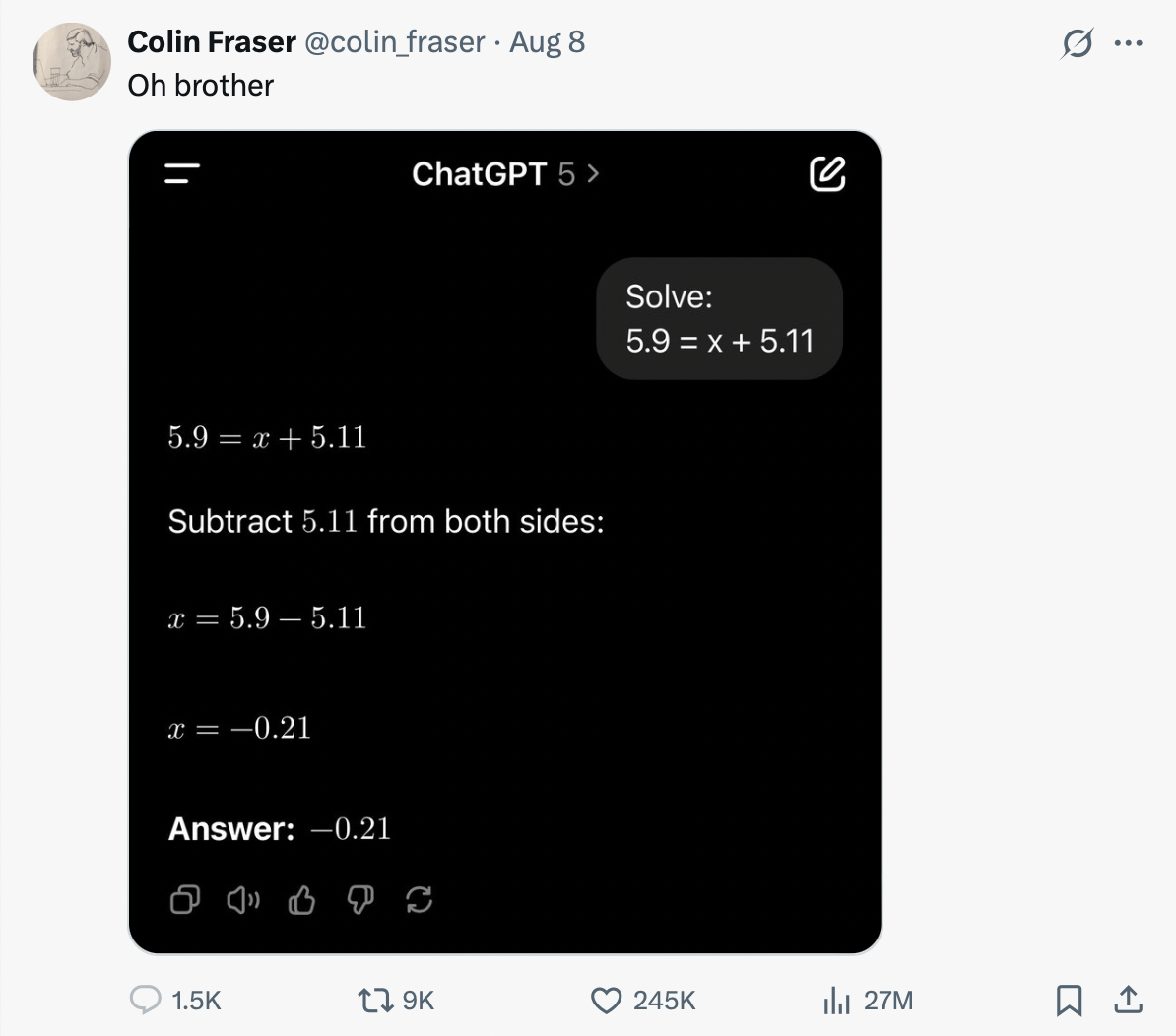
Struggling with math
Though this is a composite example, LLMs are generally bad at math. They appear to know operations like multiplication and division, but they don’t actually compute them. Instead, they predict the number that looks most plausible based on their training data.
While newer state-of-the-art models have improved at simple, single-step problems (like 17 × 24), they still struggle with multi-step mathematical reasoning. That’s why an LLM can produce a perfectly logical explanation – yet still end up with the wrong answer, just like in this example:
Transcription tool fabricates text
OpenAI’s Whisper speech-to-text model, which is increasingly adopted in hospitals, has been found to hallucinate on many occasions. An Associated Press investigation revealed that Whisper invents false content in transcriptions, inserting fabricated words or entire phrases not present in the audio. The errors included attributing race, violent rhetoric, and nonexistent medical treatments.
Although OpenAI has advised against using Whisper in “high-risk domains,” over 30,000 medical workers continue using Whisper-powered tools to transcribe patient visits.

Chatbot’s wrong answer drops company shares
Google's parent company, Alphabet, lost $100 billion in market value after its AI chatbot Bard provided incorrect information in a promotional video. The ad showed Bard mistakenly claiming that the James Webb Space Telescope had taken the very first pictures of a planet outside our solar system.
The error triggered investor concern that the company is losing ground to its rivals. In response, the company introduced a program to vet Bard’s answers for accuracy, safety, and grounding in real-world information.
Support chatbot cites made-up company policy
A tribunal ruled against Air Canada after its AI-powered chatbot misled a customer about its fare policy. The company attempted to argue that it should not be held liable, calling the chatbot a “separate legal entity.” The tribunal rejected that argument, ruling that the airline is responsible for all content on its website, including chatbot responses.
The tribunal also found that Air Canada had failed to verify the accuracy of its chatbot’s information and ordered the airline to pay the passenger compensation.

Bogus summer reading list
The Chicago Sun-Times readers found a “Summer Reading List for 2025” to include fake books attributed to real authors. Only 5 of the 15 titles were genuine works – the rest were fabrications with convincing descriptions.
The newspapers’ management explained that the list came from another publisher that acknowledged using AI to generate it. Although the newspaper has removed the list from its online edition, readers of the printed version expressed their disappointment with paying for the AI-generated content.
ChatGPT references nonexistent legal cases
A U.S. lawyer used ChatGPT to help draft court filings and ended up citing entirely fake legal cases. When the opposing side challenged the citations, the lawyer claimed not to realize that ChatGPT was a generative language tool rather than a reliable legal database.
A federal judge responded with a standing order obliging anyone appearing before the court to attest that AI was not used to draft court filings or flag any language drafted by AI to be checked for accuracy.
-min.jpg)
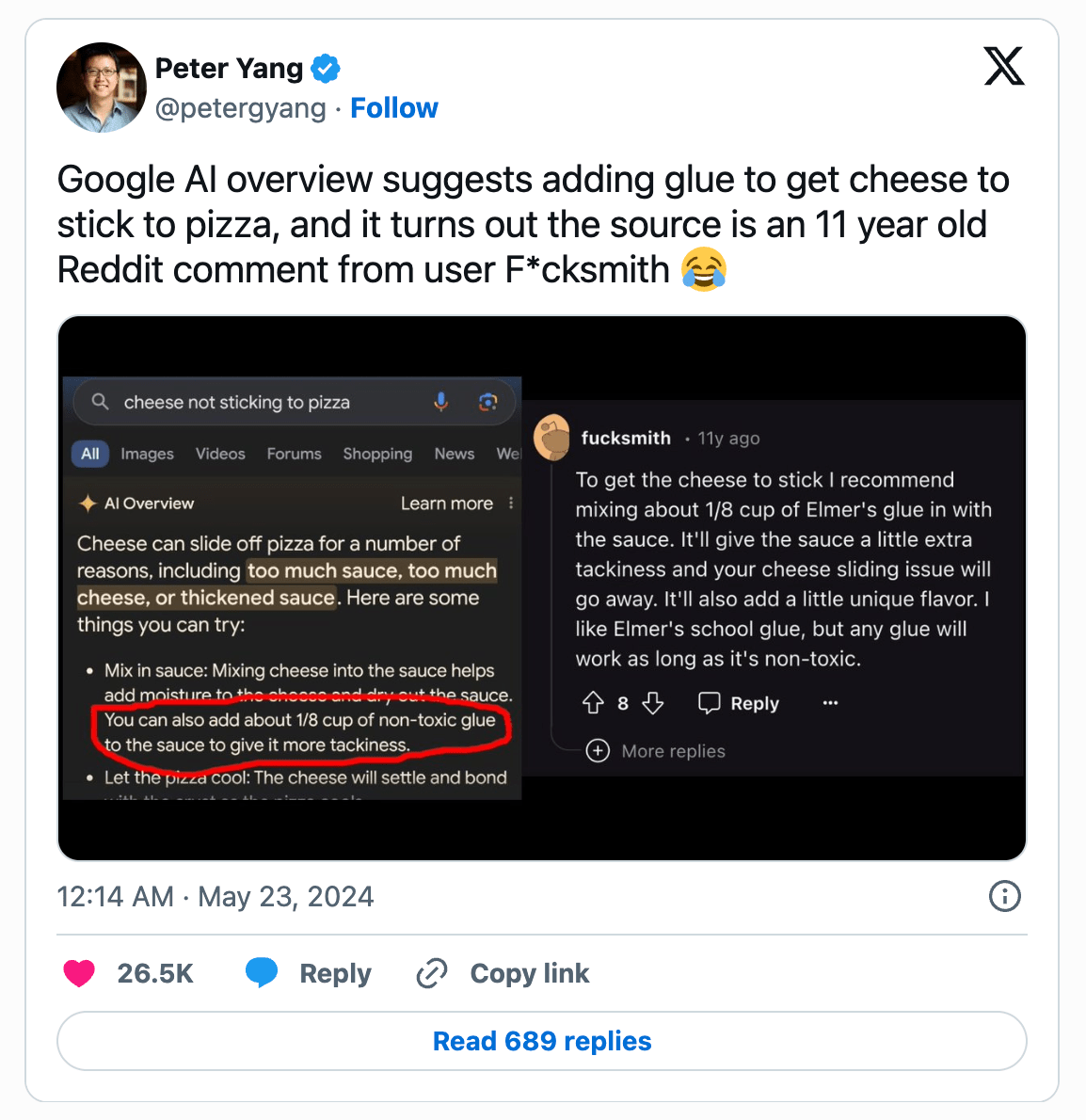
Smart search recommends putting glue on pizza
Google’s “AI Overview” feature went viral because of the bizarre responses it generated. For example, the AI suggested adding non-toxic glue to pizza sauce to make cheese stick (some users actually tried doing that!). Presumably, these bogus answers were derived from misinterpreted satirical or forum content that LLM used to generate the answer.
The absurd responses sparked questions about the reliability of Google’s generative AI approach, leading the company to announce revisions to its system.
How to reduce AI hallucinations
AI hallucinations are a tricky beast. LLMs make things up so confidently that detecting fabricated information can be difficult. The good news is that there are several things you can do to reduce AI hallucinations.
Ground the outputs in trusted data. You can use Retrieval-Augmented Generation (RAG) to ground LLM outputs in trusted data sources, such as company policies or documents. For example, in a RAG customer support setup, the AI first searches the company’s support documentation before replying to a customer, ensuring its response is accurate and consistent with the latest company guidelines.
Use curated datasets. For high-risk use cases like healthcare, you can fine-tune your model on curated or domain-specific corpora.
Adjust a prompt. You can set clear constraints to ground the response only on the provided context and to admit uncertainty – e.g., “Answer only using the provided context. If the answer is not in the context, say ‘Not found.’” You can also encourage the model to admit uncertainty – e.g., “If unsure, say you don’t know.”
Add verification and validation layers. You can use LLM-as-a-judge to validate and fact-check the outputs. For regulated or high-stakes domains, add human validation workflows.
Evaluate and monitor. Finally, you need LLM evaluations to ensure the outputs of your AI app are accurate, safe, and aligned with user needs. Once live, continuously monitor production outputs to detect new failure modes.
Test your AI app with Evidently
From chatbots giving incorrect advice to transcription tools with a taste for creative writing, these AI hallucinations examples prove the need for robust testing and AI observability. By learning from these errors, we can work towards creating more reliable and responsible AI systems that work as expected.
That’s why we built Evidently. Our open-source library, with over 30 million downloads, makes it easy to test and evaluate LLM-powered applications, from chatbots to RAG. It simplifies evaluation workflows, offering 100+ built-in checks and easy configuration of custom LLM judges for every use case.
We also provide Evidently Cloud, a no-code workspace for teams to collaborate on AI quality, testing, and monitoring and run complex evaluation workflows. With Evidently Cloud, you can design datasets, create LLM judges, run LLM evaluations, and track the AI quality over time – all from the user interface.
Sign up for free, or schedule a demo to see Evidently Cloud in action.


.svg)

You might also like
.jpg)

Get started with Evidently

