

LLM Evals
How to align LLM judge with human labels: a hands-on tutorial

contents
Imagine you are building an LLM-powered application – perhaps a chatbot, an AI assistant, a tool that drafts emails, or any other AI-driven feature. At some point, you face the task of LLM evaluation: you need to assess the quality of outputs you get.
You may consider aspects such as response tone, safety, helpfulness, or brand alignment. However, these criteria are often subjective and difficult to measure automatically. While humans can assess them well, human evaluation doesn’t scale: you can’t just keep looking and re-reading all the responses you get!
A common solution is “LLM-as-a-judge,” where you set up a process to call an LLM to evaluate your AI application’s outputs. The idea behind this approach is to use an LLM to automate human labelling – just like you would instruct a human expert to grade the responses, you can do the same with a general-purpose LLM.
This approach is flexible and efficient, but it introduces its own challenge – the evaluator itself is non-deterministic, and needs to be tuned to perform well.
As a result, your LLM evaluator requires its own evaluation! The key here is to ensure that an LLM judge aligns with human labels.
In this blog, we will:
- Briefly explain what LLM-as-a-judge is.
- Walk through the process of designing, testing, and refining such an LLM evaluator step by step.
- Give a practical tutorial showing how to create an LLM judge that evaluates the quality of LLM-generated code reviews.
What is an LLM judge?
LLM-as-a-judge is a technique that uses one LLM to evaluate the outputs of another based on predefined criteria.
Say, you want to evaluate your chatbot’s responses. You define criteria that matter to your use case – e.g., relevance, helpfulness, or coherence – and ask an LLM to be the judge and classify the provided responses. You can ask the LLM to return categorical labels or numerical scores (we generally recommend using binary or a few classes).
At the core of the judge is the evaluation prompt – this is the primary instruction you give to the LLM explaining how to score the responses.

How to create an LLM judge?
The main purpose of an LLM judge is to successfully replicate human judgment.
So the first starting point is to define what you want to assess (e.g., tone, helpfulness, or safety). You can begin by looking at your system’s outputs and labeling examples as you would judge them yourself. This lets you express and clarify your own criteria.
Once you’ve performed your own labeling, you can treat those labels as the “target”. The next task is to write an evaluation prompt for the LLM that results in the LLM (hopefully!) assigning the same labels as you did yourself.
To assess how well this prompt performs, you can run your LLM judge on the same data and measure how many labels it got right. If the quality of the judge is not satisfactory, you may need to iterate and tweak your prompt until the evaluator aligns well with human judgment.
It may sound complicated at first, but no worries – we’ll walk you through the process step-by-step.
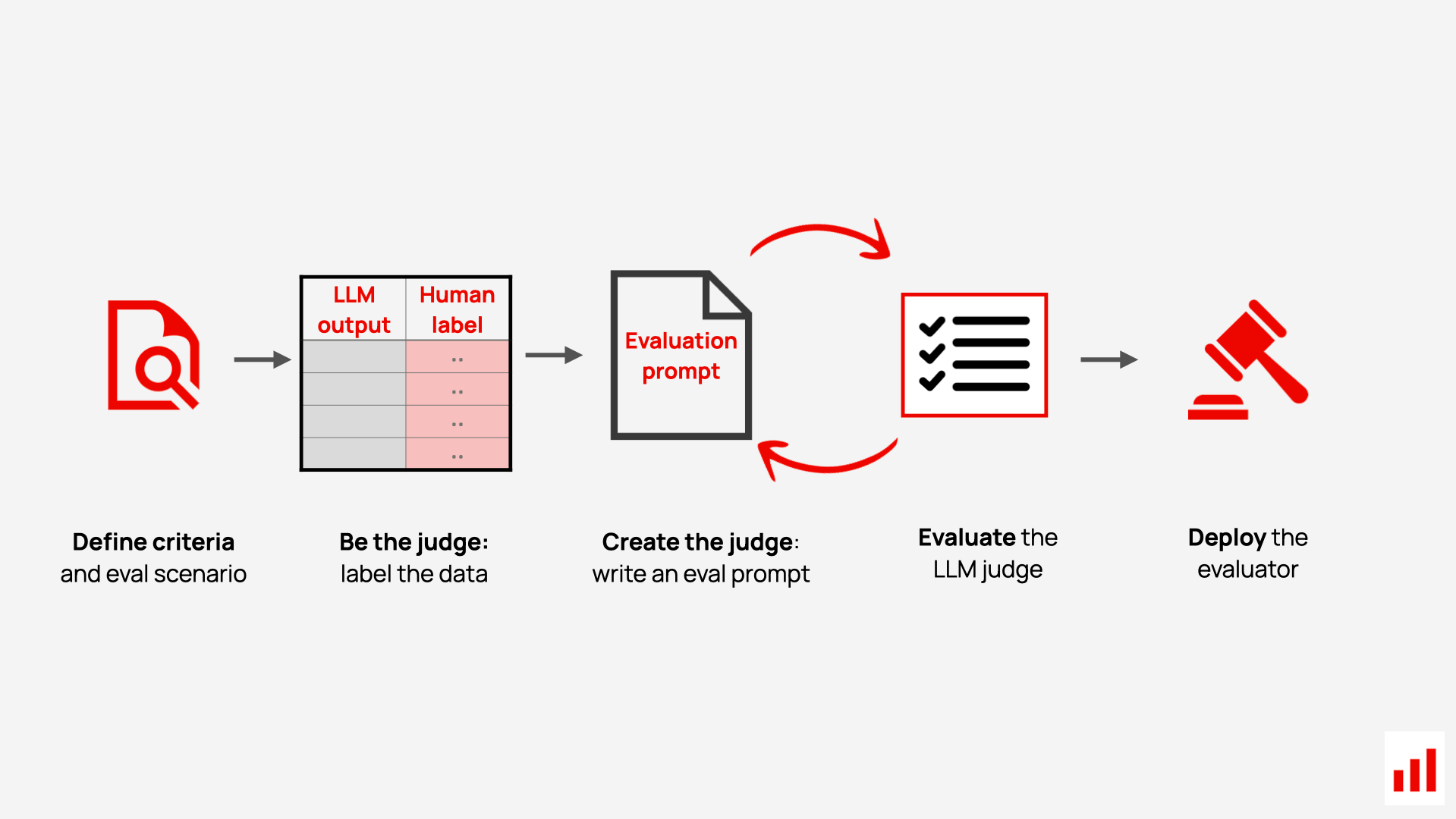
1. Define what to evaluate
The first step in evaluation is to define exactly what you’re judging. It all depends on your goals and use case, but here are a few examples of how you can use LLM evaluators:
- Failure modes detection. You can use an LLM judge to detect specific known failures, such as when your AI assistant unreasonably refuses to answer or misses instructions.
- Assessment of output quality. Depending on the application, you can use LLM to define whether your system’s outputs are faithful to context, relevant, use the correct tone, and so on.
- Scenario-specific evaluations. You can also use LLM judges to test how your system handles adversarial inputs, brand-sensitive topics, or edge cases. In these cases, you’d typically create an LLM judge to verify that the responses to the probing questions adhere to your safety rules.
- User behavior analytics. You can use a judge as a classifier to understand how users interact with your AI system, such as by sorting responses by topic, query type, or intent.
Tip: Instead of building one general evaluator, create multiple “small” judges, each targeting a specific behavior or quality metric. Narrowly scoped evaluators work best.

2. Label the dataset
Manually label your data – just as you want the LLM judge to do later.
If you have existing user logs, you can curate a dataset of real responses. If not, you can start with synthetic inputs first and then collect and review the outputs from your LLM system.
Once you have the data, review the outputs and assign the labels. You can start with 30-50 examples, but of course, the more the better!
This labeled dataset will serve as your “ground truth,” reflecting your preferred judgment criteria. You will rely on these labels to measure how well the LLM judge performs.
As you label the data, ensure that your criteria are clear enough so that you can communicate them to another person to follow. If a human can apply your rubric consistently, an LLM can likely do the same.
Tip: Stick to binary or few-class labels to maintain consistent and interpretable judgments. Arbitrary numeric scales, such as 1–10, rarely work well.

3. Write the evaluation prompt
Once you know what you’re looking for, it’s time to generalize your labeling criteria in an LLM judge evaluation prompt.
Think of it as giving instructions to an intern – make sure your instructions are clear and specific, and provide examples of what “good” and “bad” mean for your use case.
You can write the prompt yourself or use methods to generate the evaluation prompt from your labels and free-form feedback: we implemented this approach in the Evidently open-source library.
Tip: If you use a tool with built-in prompts, test them on your labeled data first to ensure the rubric matches your expectations.
4. Evaluate and iterate
Once you have your evaluation prompt, apply it to your test dataset and compare the LLM judge’s labels to human labels. You can treat this as a simple classification task and use metrics such as accuracy, precision, and recall to assess the quality of classification.
Your goal is to assess how well the LLM judge aligns with human judgments. If you are not happy with the results, adjust the prompt and rerun the evaluation.
Tip: You can also consider using correlation metrics, such as Cohen's kappa coefficient, which is typically used to evaluate the agreement between human annotators.

5. Deploy the LLM judge
Once your judge aligns with human preferences, you can use it to replace manual reviews with automated labeling.
Voila! Now you can iterate on prompts or models and use the LLM judge to quickly measure whether your system’s performance improves.
Code tutorial: code reviews quality evaluation
Now, let’s apply this process to a real example – we will create and evaluate an LLM judge to assess the quality of code reviews.
In this tutorial, we will:
- Define the evaluation criteria for an LLM judge.
- Create an LLM judge using different prompts/models.
- Evaluate the quality of the judge by comparing results to human labels.
We will use Evidently, an open-source LLM evaluation library with over 30 million downloads.
Let’s get started!
Code example: follow along with this example notebook or watch the video tutorial.
[fs-toc-omit]Getting started
Install Evidently and run the necessary imports:
!pip install evidently[llm]You will also need to set up your API keys for LLM judges. In this tutorial, we will use OpenAI and Anthropic as LLM evaluators.
Dataset and evaluation criteria
Here is the use case we deal with: let’s imagine we have an LLM system that leaves review comments on pull requests. The goal is to provide the users with helpful and constructive comments on their code.
Our goal is to ensure that the reviews provided by the LLM are actually useful in the way we intend them to be. That’s what we are going to use the LLM judge for.
We will start from step 2 of our process: let’s assume we already have LLM-generated code reviews, and the human expert has already annotated them.
The result is the dataset containing 50 human-labeled code reviews. 27 of them are classified as “bad” and 23 as “good.” Each record includes:
- The generated review
- The expert-assigned label (good/bad)
- An expert comment explaining the rationale behind the label

Tip: Bring in domain experts to curate your “ground truth” dataset. They help determine which behaviors or topics the LLM should detect and shape the guidelines that inform evaluation prompts.
This dataset is the “ground truth” for our example. As you can see, the reviews are mainly judged by actionability (do they offer clear guidance?) and tone (are they constructive or harsh?).
Now, let’s generalize these criteria in a prompt.
Experiment 1: Initial prompt
We will start with a basic prompt to express our criteria:
A review is GOOD when it’s actionable and constructive.
A review is BAD when it’s non-actionable or overly critical.In this tutorial, we use an Evidently LLM evaluator template that handles the generic parts of the prompt, such as structured output and step-by-step reasoning, allowing us to define only the evaluation criteria and target labels.
We will use GPT-4o mini as an evaluator LLM.
Now, let’s see how well our initial prompt matches the expert labels. We will use classification metrics, such as accuracy, precision, and recall, and visualize the results using the Classification Report in the Evidently library.

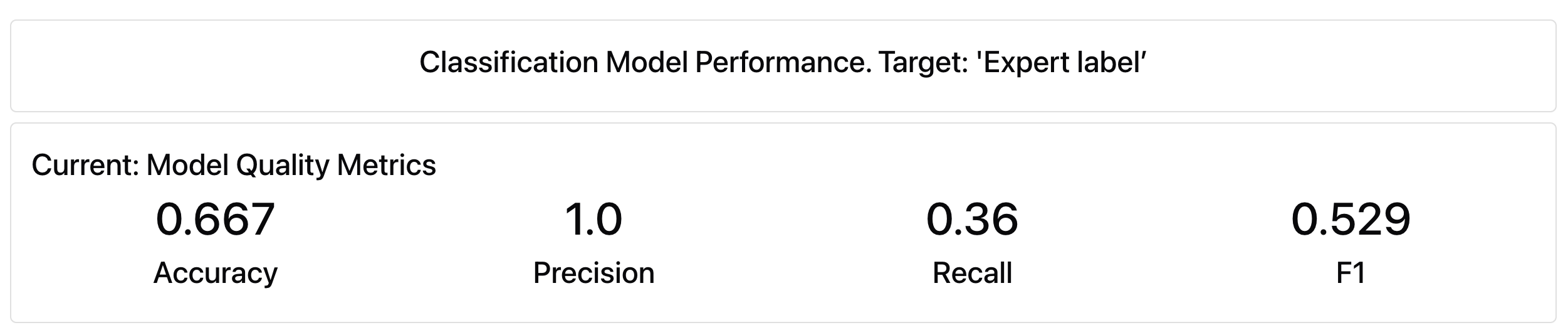
As we can see, the judge agreed with human experts on only 67% of the labels.
A 100% precision score means that every review flagged as “bad” by our evaluator was indeed bad. However, the low recall shows it missed many problematic cases – the LLM judge made 18 errors.
Let’s see if a more detailed prompt can improve the results!
Experiment 2: More detailed prompt
We can examine the expert comments more closely to define “good” and “bad” reviews in greater detail.
The refined prompt can look like this:
A review is **GOOD** if it is actionable and constructive. It should:
- Offer clear, specific suggestions or highlight issues in a way that the developer can address
- Be respectful and encourage learning or improvement
- Use professional, helpful language—even when pointing out problems
A review is **BAD** if it is non-actionable or overly critical. For example:
- It may be vague, generic, or hedged to the point of being unhelpful
- It may focus on praise only, without offering guidance
- It may sound dismissive, contradictory, harsh, or robotic
- It may raise a concern but fail to explain what should be doneTip: You can also use an LLM to help you optimize the prompt.
Let’s re-run the evaluation:

Much better!
We achieved 96% accuracy and 92% recall – more explicit evaluation criteria made a big difference. The judge misclassified only two reviews.
The results are good enough, but there are still a few more improvements we can make!
Experiment 3: Explain the reasoning
For this experiment, we will use the same prompt but explicitly ask the judge to explain the reasoning:
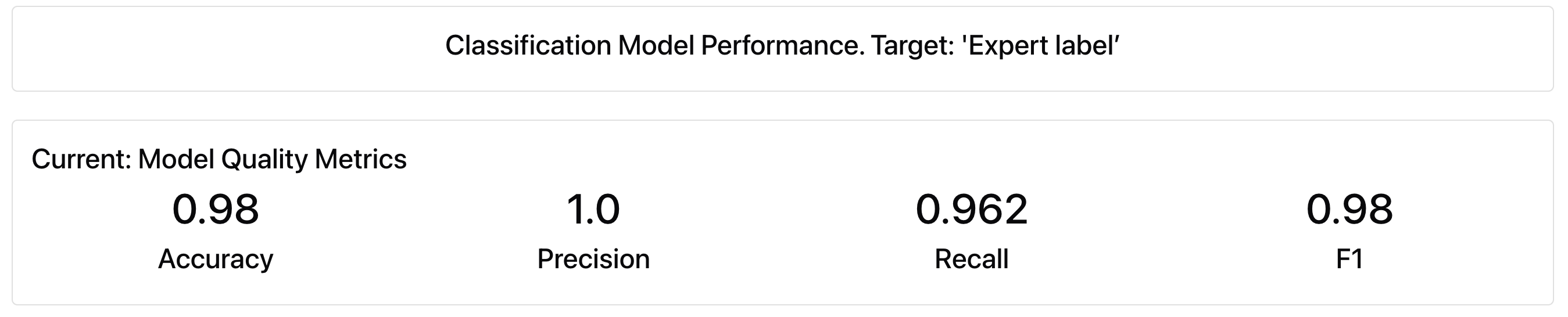
Always explain your reasoning.Here are the evaluation results – adding a single line boosted performance to 98% accuracy, resulting in just one error across the entire dataset.
Experiment 4: Different models
Once you are satisfied with your prompt, you can test it with a more cost-efficient model. In this experiment, we used GPT-4o mini as the baseline and re-ran the same prompt with GPT-3.5 Turbo:
- GPT-4o mini: 98% accuracy, 92% recall
- GPT-3.5 Turbo: 72% accuracy, 48% recall

This performance gap highlights an important point: the prompt and model must be tuned together. Simpler models may need adjusted prompting strategies or additional examples to perform well.
Experiment 5: Different providers
We can also test how our LLM judge performs across different providers.
Let’s see how it does with Anthropic’s Claude:

Both models reached the same high accuracy, though their error patterns differed slightly.
[fs-toc-omit]Experiment results
The table below summarizes the experiment results for the scenarios we tested:
Tip. You can also separate an additional small hold-out dataset for the final evaluation of your LLM judge.
We can now choose the best-performing LLM judge and deploy it to production!
Summing up
In this tutorial, we walked through an end-to-end workflow for building an LLM judge to assess the quality of code reviews. We defined evaluation criteria, prepared an expert-labeled dataset, crafted and refined the evaluation prompt, tested it across different scenarios, and iterated until our LLM judge aligned closely with human judgments.
You can adapt this example to your own use case. Here are some learnings to keep in mind:
Be the judge first. Your LLM judge should scale human expertise, not replace it. Start by labeling a representative sample yourself – this helps clarify what “quality” means in your context. Use these examples and comments to define the criteria for your evaluation prompt.
Prioritize consistency. Perfect alignment with human judgment isn’t always necessary (humans can disagree, too!). Instead, aim for consistent, repeatable outcomes from your LLM judge.
Use multiple specialized judges. Instead of one all-encompassing evaluator, consider splitting the criteria into separate judges. For example, use one for tone and another for actionability.
Start simple and iterate. Begin with a basic evaluation prompt and refine it as you identify failure patterns.
Test with different models. Your evaluator’s performance depends on both the prompt and the model. Try multiple models to compare trade-offs in accuracy, speed, and cost.
Monitor and tune continuously. An LLM judge behaves like a lightweight machine learning system: it benefits from ongoing monitoring and periodic recalibration as your product evolves.


.svg)

You might also like
-min.jpg)

Get started with Evidently

