

LLM Evals
F.A.Q on LLM judges: 7 questions we often get
-min.jpg)
contents
LLM-as-a-judge is a simple idea that has become very popular for testing and evaluating AI systems. It means using a large language model (LLM) to evaluate the responses produced by an LLM system, such as a chatbot or AI agent.
Instead of having human experts manually check if every answer is relevant, polite, or otherwise fitting the expected behavior, you can ask an LLM judge to do this automatically by following a written set of instructions (an “evaluation prompt”).
This approach helps teams check the quality and safety of AI outputs at scale – for example, when experimenting with prompts, running stress tests, or monitoring systems after launch.
At Evidently, we’ve implemented LLM judges in our open-source library and Evidently Cloud observability platform.
In this blog, we’ll answer some of the most common questions we get about how LLM judges work and how to use them effectively.
1. What grading scale to use?
Some LLM judge implementations use numeric rubrics – for example, asking an LLM to score responses from 0 to 100 or on a 1-10 scale. This may look convenient, but in practice it rarely works well. LLMs are not calibrated to produce consistent scores on arbitrary scales or topics. A very similar response might get a “7” in one run and a “9” in another.
We recommend using binary or a few clearly defined classes. And when you use several classes, it’s best to avoid vague numeric ranges like 1-10. Instead, create named categories that describe clear qualitative differences.
For example, let’s say you are using an LLM judge to assess correctness between two responses – your ideal target answer and the new answer produced by the system. Don’t ask the model to rate “correctness” on a 1-10 scale. That doesn’t mean much to either humans or LLMs. Instead, define in your prompt what “correct” actually means for your use case.
For example: Do you care about specific types of differences, such as omissions, additions, or contradictions? Are some specific changes acceptable? For instance, if the reference answer uses an abbreviation and the new response spells it out fully, should that count as a difference? Clarifying these rules inside the judging prompt makes the task concrete.
You might end up with a small set of defined categories that fit your needs, such as:
- Fully correct (within your definition of correct matching).
- Correct but incomplete.
- Contradictory.
When you have a clear definition of each category, an LLM will be able to apply the grading rubric more precisely.
Here is a simple rule of thumb to test your evaluation setup: can a human apply your judging prompt consistently? If not, rewrite it until they can. Then, test how well an LLM can do that.
This also demonstrates why numeric scales like 1-10 tend to fail: people will often disagree on whether something deserves a 6 or a 7, and the same ambiguity will confuse your LLM judge. Clear, named categories lead to more stable, interpretable, and useful evaluations.
2. Where do I start to create a judge?
Start by deciding what you actually want to evaluate.
You rarely get a meaningful LLM judge rubric without first labeling some outputs by hand. So you must begin by reviewing real responses to assess the quality of your system’s outputs – go through real logs or sample generations. This helps you spot real patterns: recurring error types, edge cases, and what “good” versus “bad” looks like.
In short: be the judge before you build the judge.
If you don’t yet have real data, you can prepare synthetic input examples. Here, you prompt an LLM to generate realistic inputs for your use case – for example, user questions or even full question-answer pairs for a RAG system.
This process helps you express your assumptions about who the users are and what they might ask. Then, you run these inputs through your LLM application and capture the generated responses you can now review.
Whoever does this manual labeling and annotation must understand the domain or product deeply. If your product serves a niche – like legal drafting, medical advice, or financial analysis – this likely means directly involving subject matter experts in the review process. Either way, the person doing the review must have a clear understanding of what “good” means in your context and be able to apply that judgment consistently.
You can start by labeling outputs as Pass/Fail/Unclear – and adding free-form notes about what works and what doesn’t. Then, you can analyze these notes to identify recurring patterns and turn them into structured evaluation categories, like correctness, clarity, tone, or factual accuracy.

When you reach the point where your evaluation rubric and guidelines are clear enough that another human could apply them consistently – that’s a good moment to translate them into an LLM judge.
The key takeaway: evaluation is about scaling human judgment, not replacing it.
A good LLM judge captures what your experts already know and turns that intuition into a repeatable, automated process. It’s not a plug-and-play metric – it’s an analytical design task that starts with understanding your data and your product.
Who actually builds the judge depends on your setup. Sometimes it’s a domain expert using a no-code tool; other times it’s a data scientist working closely with them. Either way, the person leading evaluation design must understand both the domain and the nuances of the task.
3. Which LLM to use as a judge?
You can make this decision the same way you would for your main LLM product. Since most evaluation tasks are essentially open-ended classification, almost any general-purpose LLM can serve as a judge.
In general, it makes sense to use the most capable model available – but it always depends on your task. If you need to evaluate large volumes of data, you can balance cost and speed by using smaller models for simpler checks.
Some evaluation tasks are relatively straightforward – for example, sentiment analysis, topic detection, refusal or denial detection, or checking whether a response includes a specific term or fits a certain format. These can be handled well by smaller, cheaper models.
Other tasks are more complex or involve long or nuanced inputs – such as analyzing multi-turn conversations, comparing answers to context, or following a detailed content moderation guide. In those cases, a larger, more capable LLM with a long context window is justified.
4. Can I use the same judge LLM as the main product?
Some practitioners prefer not to use the same LLM for both generation and evaluation, assuming it might be biased toward its own outputs.
You may come across such research discussing biases in LLM judges, but it’s important to understand what this usually refers to. Many of those studies focus on open-ended pairwise comparisons, where a model decides which of two responses to the same input is “better.” In those side-by-side settings, researchers have observed that an LLM might favor answers produced by the same model family or written in a certain verbose style.
However, in practice, when you build LLM judges for product evaluation, your use cases are typically much narrower and more concrete. You’re not comparing two responses but asking targeted questions about a specific generation, such as:
- Did the user express frustration during the conversation?
- Was the task completed successfully?
- Does the answer meet the defined safety requirements?
- Does the response cover all key points from the reference?
These are specific, bounded checks with little room for stylistic preference or model-family bias. In these cases, the quality of the judgment depends far more on the clarity of your evaluation prompt and the capabilities of the model, rather than on which model family produced the output.
So yes – you can often use the same LLM as both the generator and the judge. Just make sure you formulate a distinct, clear prompt for evaluation.
That said, sometimes it helps to use a different model (or even several). For example, when your evaluation rubric is not yet well defined, or when the task itself is ambiguous – like deciding whether an email sounds “professional” or if a marketing text “fits the young audience”.
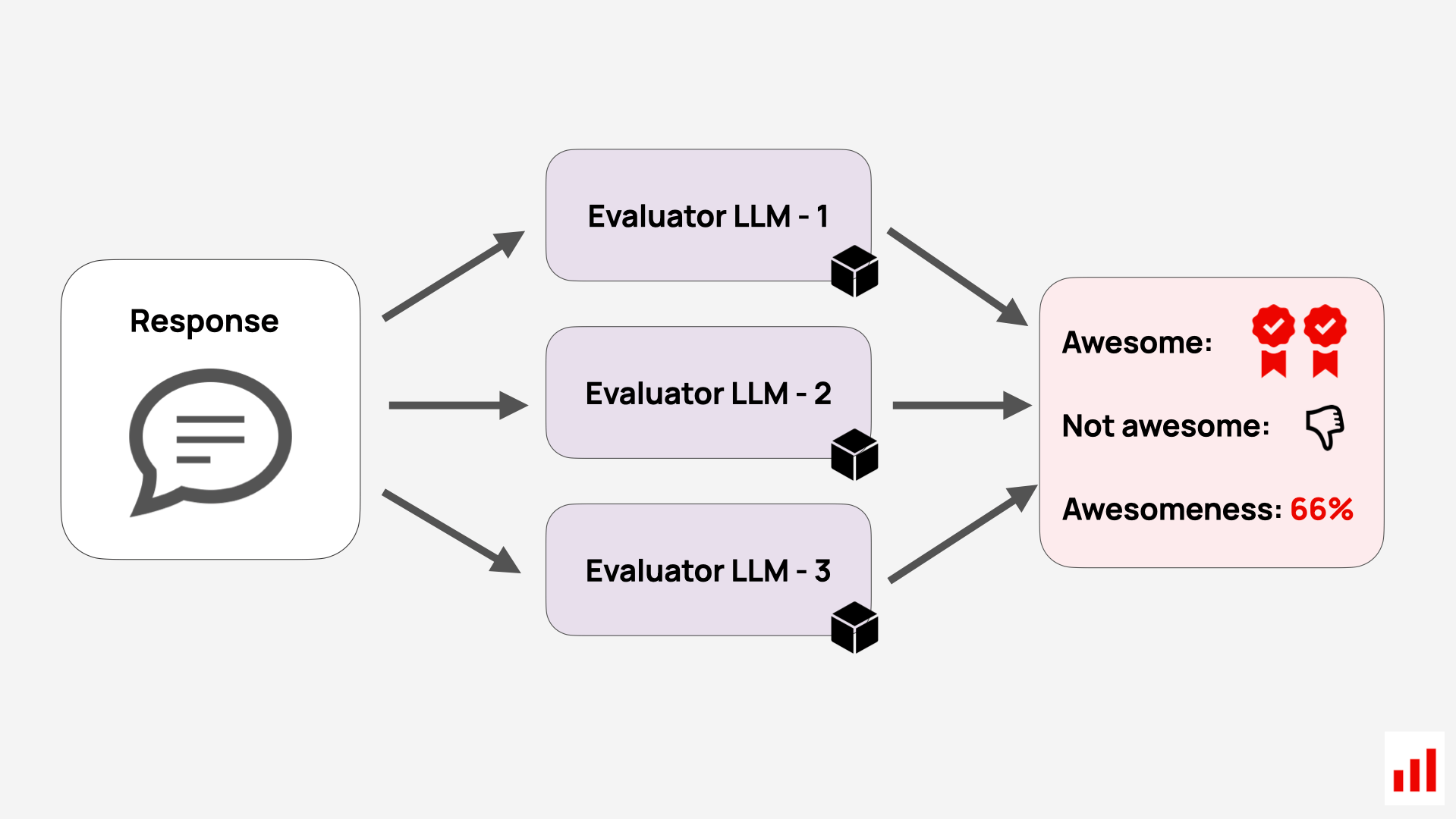
In those early stages, you can experiment with LLM juries, where multiple models provide judgments that you then aggregate. This can help you spot inconsistencies and calibrate your criteria before locking in your main judge.
You can also use multiple judges for high-risk assessments as a kind of second opinion – for instance, when evaluating safety, compliance, or sensitive content. An agreement between independent judges can serve as an additional quality signal before you act on the results.
5. How do I trust an LLM judge?
An LLM judge is not a fixed model or a universal metric. It’s a technique you implement for a specific use case – which means you shouldn’t trust it blindly. Its reliability depends entirely on how the judge is built and the complexity of the task.
Each judge has its own prompt, model, rubric, and type of outputs it is applied to. So there’s no meaningful way to claim that “LLM judges work” or “don’t work” in general. What matters is whether your judge works for your task.
You can think of it as building a miniature classifier.
First, you define what you want to detect – for example, whether an answer is correct compared to a reference, or whether it meets your definition of safety or compliance. Then, you create your “classifier” using an LLM prompt that will predict the class.
Since the goal of this classifier is to replicate human judgment, you should evaluate its reliability the same way you would evaluate a traditional predictive ML model – by comparing the model's judgments against the ideal human ones.
Here is a simple process to do that:
- Label a small dataset manually, using the same criteria you want the judge to apply.
- Run your LLM judge on that same dataset.
- Compare results using standard metrics such as accuracy, precision, recall – depending on which type of error matters most to you.

For instance, if your goal is to catch every unsafe response, you might prioritize recall even if it means some false positives. You can also measure agreement or correlation between your LLM judge and human annotators, similar to inter-rater reliability tests.
How to create and tune an LLM judge: in our tutorial example, we show how to systematically improve an LLM judge prompt until its labels closely match human annotations.
Just like with your main product prompts, expect to iterate and refine your judge. Small changes in phrasing, examples, or output format can noticeably shift results. You can even auto-tune your judge using a labeled dataset to optimize prompt wording until its labels align closely with human annotations.
The key takeaway: don’t assume your LLM judge is correct – measure it.
6. How to write a good evaluation prompt?
An evaluation prompt is yet another instruction for LLM. So, most of the classic prompt-writing principles apply.
Writing a good prompt is like delegating a task to an intern – you need to provide all the necessary context and clear instructions. This is especially important for vague criteria like “completeness” or “safety,” where you must make these expectations explicit. Examples help a lot here. Ideally, you can link the evaluation to specific patterns or behaviors.
For instance, instead of asking “How complete is the advice?”, define what “complete” means in your context – for example:
- Does it include an actionable plan?
- Does it reference at least one source?
- Does it recap the user’s request?
That way, the judge has something concrete to look for.
As we discussed in Q1, it also makes sense to ask the LLM to classify the output using binary or low-precision scoring with explicit class definitions. These tend to be more reliable and consistent for both LLMs and human evaluators.
You can also include guidance on handling unclear cases directly in your prompt. For example, if you prefer to flag borderline responses rather than miss them, add an instruction like: “If unsure, err on the side of caution and mark the response as ‘Incomplete’.”
In the past, the frequent recommendation was to include few-shot examples directly in the judgment prompt. With newer, more capable models, it often makes sense to use examples more selectively – such as to illustrate specific, potentially confusing cases rather than filling the prompt with multiple input-output pairs. In either case, you should always test how adding examples affects the quality of the judge.

Finally, it helps to encourage the (non-reasoning) LLM to perform step-by-step reasoning, not just return a final label. Essentially, we talk about applying the chain-of-thought approach before giving the final answer.
This improves both the quality of the judgment and the interpretability of results for humans reviewing them later.
We’ve implemented many of these principles in the Evidently open-source library, which offers ready-made LLM evaluation templates with structured formatting and reasoning steps. You can add your own criteria in plain text or use built-in prompts for inspiration.
To create judges without code, you can also sign up for a free account on Evidently Cloud.

7. Which metrics to choose for my use case?
Many teams come asking for ready-made LLM evaluation metrics to assess the quality of their LLM products – hoping to pick from a list of predefined options.
But the idea of using pre-built LLM judges should be approached with caution. Copying someone else’s evaluation schema rarely gives you the insights you need. Unless your task is extremely standardized (like a universal content moderation policy), it won’t fit perfectly.
Additionally, not every criterion may be truly relevant for your use case. For example, fluency or coherence rarely matter with modern LLMs – most are already very polished. Applying such metrics won’t tell you much about your product, and can even create a false sense of security when you “always pass the test” but fail on more important dimensions.
At the same time, if you’re working with a smaller local model, checking fluency might make perfect sense as an evaluation criterion. However, even in this case, it would often make sense to formulate or adapt your own definition of fluency rather than borrow pre-built metrics.
Ultimately, the best evaluations are context-aware – tailored to your product and its goals – and discriminative so that they can highlight meaningful differences. For instance, if every output always passes your evaluation, the metric likely isn’t useful. Or, if you have multiple metrics that are perfectly correlated, you can probably keep just one.
There are two main ways to design meaningful custom metrics for your product.
1. Bottom-up.
This is the most common approach for open-ended systems and experimental or production quality evaluations. Here, you start by analyzing your own data – collect real outputs (from tests or production), review them manually, label them, and look for recurring failure types. Then, turn these insights into specific criteria such as factual accuracy, clarity, tone, or task completion success.
This approach takes effort but gives the richest signal. Often, you’ll discover problems you didn’t anticipate – vague answers, hallucinations, or unhelpful phrasing – and can formalize them into clear evaluation criteria.
Of course, here you can draw inspiration from common metrics like faithfulness for RAG systems or tool-call correctness for agents, but always adapt them to what you actually observe. Some errors may almost never happen – those checks can be dropped, while new or unexpected issues may need custom metrics.

Importantly, there is no strict requirement for how many metrics you use – it depends on your setup. You might have a single pass/fail evaluation if your judge can handle all aspects at once, or separate checks for each quality dimension.
Even if you use multiple metrics, you can still combine their results programmatically after each judge runs. For example, flag a response as “fail” if any key check fails (incomplete, inaccurate, or irrelevant), or sum up positive scores for an overall numerical quality rating. This gives you the best of both worlds – detailed insight per criterion and a single aggregated score for decisions.
2. Top-down.
Here, you start from the use case and define the checks logically, based on your understanding of the task and risks.
This works well for narrow predictive tasks like ranking (search) or classification, where standard metrics such as accuracy, precision, recall, or NDCG make sense – you just need to design the dataset, not reinvent the metric.
It’s also a good fit for risk-focused evaluations, such as safety or adversarial testing. Here, you begin with a risk analysis: what could go wrong in your system?
For example, if there’s a chance your chatbot might give unsafe advice or recommend a competitive product, you can design targeted test cases to probe for these risks – like asking for medical advice or competitor comparisons – and then attach specific evaluators to flag them (e.g., a safety or compliance judge).
In short: choose or design metrics that match your system’s goals and risks. Good metrics are not copied – they are built to reflect what success and failure actually look like for your product.
Create an LLM judge for your AI system
LLM-as-a-Judge is a scalable alternative to human labeling. If you are working on complex AI systems like RAG or AI agents, you’ll need such task-specific evaluations tuned to your criteria and preferences.
Our open-source library with over 30 million downloads makes it easy to set up and run LLM-as-a-Judge evaluations and other tests. You can use different evaluator LLMs and test judges against your own labels to better align them.
On top of it, Evidently Cloud provides a platform to collaboratively run tests and evaluations. You can generate synthetic test data, create LLM judges with no-code, and track performance over time – all in one place.
Ready to create your first LLM judge? Sign up for free or schedule a demo to see Evidently Cloud in action. We're here to help you build AI systems with confidence!


.svg)

You might also like


Get started with Evidently

