


contents
LLMs are rapidly becoming more advanced at coding tasks, driving the development of real-world applications, from coding co-pilots to developer productivity tools to automated code reviewers. But as model capabilities grow, so does the need to measure their performance.
This blog highlights 15 LLM coding benchmarks designed to evaluate and compare how different models perform on various coding tasks, including code completion, snippet generation, debugging, and more.
Want more examples of LLM benchmarks? We put together database of 250+ LLM benchmarks and datasets you can use to evaluate the performance of language models.
HumanEval
HumanEval measures how well LLMs can generate code. It tests their ability to understand programming tasks and produce syntactically correct and functionally accurate pieces of code based on given prompts.
The dataset includes 164 programming tasks and unit tests that automatically check the model-generated code against expected results, simulating how a human developer would validate their work. A model’s solution must pass all provided test cases for a given problem to be considered correct.
Paper: Evaluating Large Language Models Trained on Code by Chen et al. (2021)
Dataset: HumanEval dataset

MBPP (Mostly Basic Programming Problems)
Mostly Basic Programming Problems (MBPP) evaluates how well LLMs can generate short Python programs from natural language descriptions. It includes 974 entry-level tasks covering common programming concepts like list manipulation, string operations, loops, conditionals, and basic algorithms. Each task provides a clear description, an example solution, and a set of test cases to validate the LLM's output.
Paper: Program Synthesis with Large Language Models by Austin et al. (2021)
Dataset: MBPP dataset

SWE-bench
SWE-bench (Software Engineering Benchmark) assesses the ability of LLMs to tackle real-world software issues sourced from GitHub. It includes more than 2200 issues and their corresponding pull requests from 12 widely used Python repositories. The benchmark challenges models to generate patches that fix the issues based on the provided codebase and issue description. Unlike simpler code generation tasks, SWE-bench requires models to handle long contexts, perform complex reasoning, and operate within execution environments.
Paper: SWE-bench: Can Language Models Resolve Real-World GitHub Issues? by Jimenez et al. (2023)
Dataset: SWE-bench dataset

CodeXGLUE
CodeXGLUE is a benchmark dataset for program understanding and code generation. It includes 14 datasets, 10 diversified programming tasks, and a platform for model evaluation and comparison. The tasks include clone detection, defect detection, cloze test, code completion, code translation, code search, code repair, text-to-code generation, code summarization, and documentation translation.
The benchmark's creators also provide three baseline models: a BERT-style model for program understanding problems, a GPT-style model for completion and generation problems, and an Encoder-Decoder framework that tackles sequence-to-sequence generation problems.
Paper: CodeXGLUE: A Machine Learning Benchmark Dataset for Code Understanding and Generation by Shuai Lu et al. (2021)
Dataset: CodeXGLUE dataset

DS-1000
DS-1000 is a code generation benchmark that focuses on data science problems. It contains 1000 coding challenges sourced from 451 StackOverflow questions. The tasks span seven popular Python libraries, including NumPy, Pandas, TensorFlow, PyTorch, and scikit‑learn.
Example tasks include realistic operations like data manipulation (e.g., Pandas DataFrame transforms) and machine learning tasks (e.g., training a model with scikit‑learn or PyTorch). Each completed task is run against test cases to check functional correctness and against constraints on API usage to make sure the generated code uses intended library functions.
Paper: DS-1000: A Natural and Reliable Benchmark for Data Science Code Generation by Lai et al. (2022)
Dataset: DS-1000 dataset

APPS (Automated Programming Progress Standard)
APPS is a code generation benchmark that measures the ability of LLMs to generate “satisfactory Python code” based on an arbitrary natural language specification. The benchmark includes 10,000 problems, collected from open-access coding websites like Codeforces or Kattis. The task difficulty ranges from one-line solutions to substantial algorithmic challenges. Each problem is accompanied by test cases and ground-truth solutions to evaluate the generated code.
Paper: Measuring Coding Challenge Competence With APPS by Hendrycks et al. (2021)
Dataset: APPS dataset

EvalPlus
EvalPlus is an evaluation framework that assesses the functional correctness of LLM-synthesized code. It extends the test cases of the popular HumanEval benchmark by 80x and the MBPP benchmark by 35x.
EvalPlus augments the evaluation dataset with large amounts of test cases produced by an automatic test input generator. It uses ChatGPT to generate a set of seed inputs for later mutation. The generator randomly selects a seed from a seed pool of ChatGPT-generated inputs and mutates it to create a new input. If the new input meets the requirements, it is added to the seed pool, and the process repeats.
Paper: Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation by Liu et al. (2023)
Dataset: EvalPlus dataset

CrossCodeEval
CrossCodeEval is a multilingual benchmark that tests LLMs' ability to perform cross-file code completion. Unlike popular benchmarks like HumnEval or MBPP, it evaluates models on completing code not just within a single file but across a project — capturing dependencies and modularity of real-world coding tasks.
The dataset is built on a set of GitHub repositories in four popular programming languages: Python, Java, TypeScript, and C#. The benchmark authors employ static analysis to extract code completion tasks that specifically require cross-file context to solve accurately.
Paper: CrossCodeEval: A Diverse and Multilingual Benchmark for Cross-File Code Completion by Ding et al. (2023)
Dataset: CrossCodeEval dataset

Repobench
RepoBench evaluates LLMs on repository-level code auto-completion tasks. It consists of three interconnected evaluation tasks:
- RepoBench-R (Retrieval) assesses the model's ability to retrieve relevant code snippets from other files to provide necessary context for code completion.
- RepoBench-C (Code Completion) evaluates the model's capability to predict the next line of code using both in-file and cross-file contexts.
- RepoBench-P (Pipeline) combines retrieval and code completion tasks to test the model's performance in handling complex scenarios that require both retrieving context and generating appropriate code.
The tasks are derived from GitHub repositories and reflect real-world programming challenges where understanding and integrating information across multiple files is essential. The benchmark supports both Python and Java.
Paper: RepoBench: Benchmarking Repository-Level Code Auto-Completion Systems by Liu et al. (2023)
Dataset: RepoBench-R, RepoBench-C, RepoBench-P

Code Lingua
Code Lingua evaluates LLMs in programming language translation. It compares models' abilities to understand what the code implements in the source language and translate the same semantics into the target language. For example, converting a function from Java to Python or from C++ to Go. The benchmark also tracks bugs introduced or fixed during translation, assessing semantic fidelity and robustness .
Code Lingua incorporates some commonly used datasets like CodeNet and Avatar and consists of 1700 code samples in five languages – C, C++, Go, Java, and Python – with more than 10,000 tests, over 43,000 translations, 1748 bug labels, and 1365 bug-fix pairs.
Paper: Lost in Translation: A Study of Bugs Introduced by Large Language Models while Translating Code by Pan et al. (2023)
Dataset: Code Lingua dataset

ClassEval
ClassEval is a manually constructed benchmark that measures how well LLMs can generate full classes of code. It consists of 100 class-level Python coding tasks covering over 400 methods. The tasks are designed to have dependencies such as library dependencies, field dependencies, or method dependencies – reflecting real-world software engineering scenarios where code isn’t isolated functions but classes.
Each coding task consists of an input description for the target class, a test suite for verifying the correctness of the generated code, and a canonical solution that acts as a reference implementation of the target class.
Paper: ClassEval: A Manually-Crafted Benchmark for Evaluating LLMs on Class-level Code Generation by Du et al. (2023)
Dataset: ClassEval dataset

LiveCodeBench
LiveCodeBench is a benchmark that evaluates the coding abilities of LLMs on 400 problems from three competition platforms: LeetCode, AtCoder, and CodeForces. The coding problems are updated over time to reduce the risk of data contamination.
Beyond code generation, the benchmark also focuses on a broader range tasks, such as self-repair, code execution, and test output prediction. Each problem is annotated with a release date, so one can evaluate the model’s performance on tasks released after the model’s training cutoff to see how well the model generalizes to unseen problems.
Paper: LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code by Jain et al. (2024)
Dataset: LiveCodeBench dataset

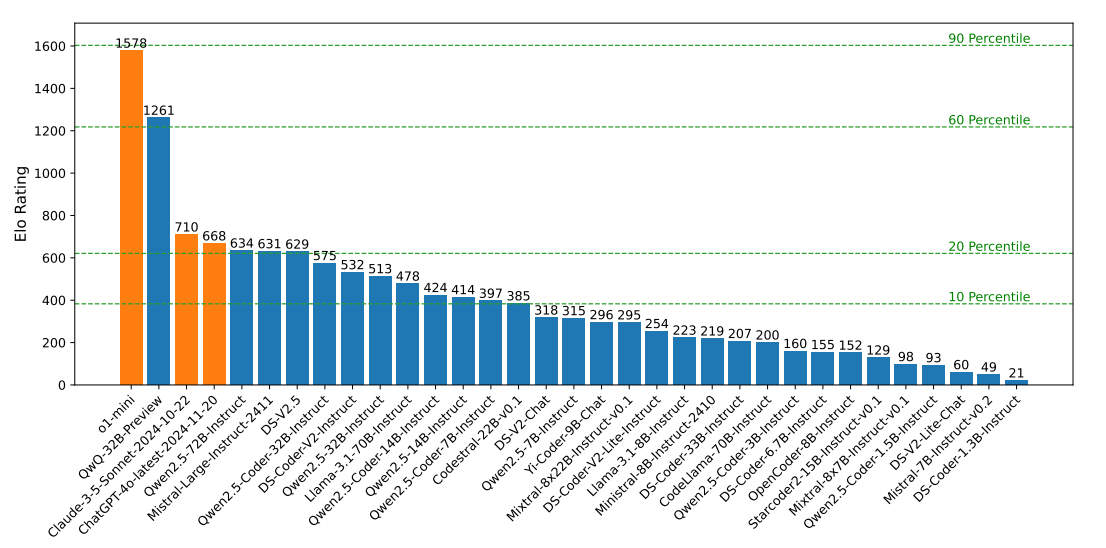
CodeElo
CodeElo evaluates how well LLMs can generate code in competition-style programming tasks. Problems are sourced from the Codeforces platform, one of the major competitive programming sites, and vary in problem difficulty and algorithms needed to solve the task.
The benchmark uses an Elo rating system common in chess and competitive games to evaluate model performance on a scale similar to that of human contestants.
Paper: CodeElo: Benchmarking Competition-level Code Generation of LLMs with Human-comparable Elo Ratings by Quan et al. (2025)
Dataset: CodeElo dataset
ResearchCodeBench
ResearchCodeBench focuses on evaluating LLMs’ ability to implement code from recent machine learning research papers. The benchmark consists of 212 coding challenges derived from top 2024–2025 papers, and LLMs are tasked to translate the conceptual contribution of each paper into executable code.
Here’s how it works: a model is given a research paper, a target code snippet, and context code; and is prompted to fill in the missing code. The generated code is then evaluated against curated tests for functional correctness.
Unlike other code generation benchmarks that test on well‐known tasks, ResearchCodeBench aims to stress how well LLMs perform on new research ideas and whether they are able to support research and innovation.
Paper: ResearchCodeBench: Benchmarking LLMs on Implementing Novel Machine Learning Research Code by Hua et al. (2025)
Dataset: ResearchCodeBench dataset

SciCode
SciCode is a research coding benchmark curated by scientists. It tests LLMs on their ability to generate code to solve real scientific problems. The dataset consists of 80 main problems decomposed into 338 subproblems in 6 natural science domains: mathematics, physics, chemistry, biology, materials science, and a computational domain.
Each task contains optional scientific background descriptions, gold-standard solutions and test cases to check the correctness of the generated code. To solve the tasks, an LLM must demonstrate its abilities in knowledge recall, reasoning, and code synthesis.
Paper: SciCode: A Research Coding Benchmark Curated by Scientists by Tian et al. (2024)
Dataset: SciCode dataset

Test your AI system with Evidently
While benchmarks help compare models, they rarely reflect the specifics of your AI application. To better fit into the scope of your use case – be it a coding copilot or developer productivity app – you need custom evaluations.
That’s why we built Evidently. Our open-source library, with over 25 million downloads, simplifies testing and evaluating LLM-powered applications with built-in evaluation templates and metrics.
For teams working on complex, mission-critical AI systems, Evidently Cloud provides a platform to collaboratively test and monitor AI quality. You can generate synthetic data, create evaluation scenarios, run tests, and track performance — all in one place.
Ready to test your AI system? Sign up for free or schedule a demo to see Evidently Cloud in action. We're here to help you build with confidence!


.svg)

You might also like
-min.jpg)

Get started with Evidently

