

Evidently
Evidently 0.7.11: open-source synthetic data generation for LLM systems

contents
When you are building an LLM system – whether a RAG pipeline, a chatbot, or a domain-specific AI agent – you need a reliable, purpose-built test dataset to ensure your system works well.
However, the early stages of LLM system development often present a bottleneck: you don’t have real data, meaningful examples, or clear evaluation criteria. And in many cases, you’re not yet ready to put the system in front of real users. So how do you move forward?
One way is to use synthetic data. Here, you prompt an LLM to create a set of inputs (and sometimes outputs) based on provided examples or context, and voila – here’s your dataset. But here’s the catch: it must also mimic the real-world data as best as possible.
To help you create test data tailored to your scenario, we built an open-source synthetic data generator tool.
It’s available as a new feature of the open-source Evidently Python library.
You can define user profiles and goals, select the LLMs, and build fully customizable, complex synthetic data generation pipelines.
In this post, we’ll explain how it works and walk through the example use cases.
⭐️ Like the idea? Give us a star on GitHub to support the project.
What is synthetic data, and when do you need it?
Synthetic data means made-up data, not taken from the real world. It’s generated – usually by another AI model – to create test cases, questions, or prompts that help evaluate how well an LLM system performs.
Is synthetic data better than real data? Not really.
But it’s very useful when the real user data is unavailable, limited, or sensitive – especially in early stages of development. Synthetic data helps fill the gaps and add diversity to your test cases.
There are many times when it’s helpful:
- Trial runs before deployment. You can generate synthetic user inputs to test your LLM product in realistic situations before you have actual users.
- Adversarial evaluations. Synthetic data can also help design rare or difficult test examples like prompt injections that might not otherwise show up in real logs.
- Targeted edge case testing. Want to see how the model handles angry users or confusing questions? You can generate examples just like that, too.
- Privacy concerns. Real data can be sensitive. Generating synthetic variations gives you similar cases without compromising privacy.
- Finally, it scales. Creating real test data by hand takes time. Synthetic data is cheap to use and allows the generation of thousands of test cases in minutes.
In short, synthetic generation gives you a faster and more controlled alternative whenever collecting real data is slow, limited, or risky.
Typically, there are two ways to use synthetic data:
- Synthetic inputs only. For example, you can generate likely user questions that fit your use case. You can also focus on adversarial queries (like prompts about forbidden topics) to run automated safety checks.
- Synthetic input-output pairs. These are complete test examples with both a question and an expected answer. This setup works well for tasks like RAG evaluation, where you want to test whether the model returns the correct response given a specific query.

Synthetic data generation with Evidently
Synthetic data only makes sense if it matches your use case well – and that's exactly what we wanted to support. So we built a tool in Evidently that helps you generate synthetic datasets with a clean, configurable setup to do it quickly and efficiently.
Here is how it works.
The module is fully customizable to give you complete control of the generated test sets:
1. You start with specifying what type of data you want to generate.
Here, you can set specific user profiles that shape the tone, intent, knowledge level, and even “quirks” of the generated inputs. Want to simulate a beginner user asking customer support questions? Or a sarcastic user tweeting product complaints? You can specify exactly that.
This helps you express your assumptions about the types of users interacting with your LLM system – who they are, and what they’re trying to do.
You can also decide whether you want just inputs (e.g. sample questions or safety probes), or full input–output pairs (like QA for RAG tests). If you're going the full-pair route, you can also pass in the source knowledge base.
2. Choose your LLM for data generation. You can select from different LLMs to power your generation. The generator is model-agnostic and can integrate with your preferred providers.
3. Run the generation. You get your synthetic dataset straight into a pandas DataFrame – clean, structured, and ready for testing or evaluation.
This workflow is fully open-source and released as part of our Evidently Python library.
Let’s look at how it works on a code example!
Example use cases
Let’s walk through a few use cases where you can apply this feature. We prepared a code tutorial that shows this new synthetic data generator.
💻 See the full code example here.
Synthetic inputs
You can generate any kind of general-purpose inputs based on a few examples and a user profile. This is helpful when you want to test how your system behaves – you need mock inputs that reflect how your users would interact with the product.
The kind of inputs you generate depends on the system you're building. For example:
- Customer support chatbot. Simulate realistic user questions with varying intents.
- Text classifier by topic. Create short texts across various subjects.
- Content moderation system. Generate toxic or off-topic messages to evaluate edge cases.
- AI tutor. Produce learner questions with varying levels of understanding, tone, or confusion.
This is free-form generation, so technically you can use it for anything – just define the examples and user behavior you want to simulate.
Say, you want to create synthetic Twitter-style posts. You can provide some example tweets and a user profile – and the generator will produce similar posts.
You can tweak parameters like role, tone, or intent to adapt the generation style to your desired user persona:
from evidently.llm.datagen import UserProfile
from evidently.llm.datagen import FewShotDatasetGenerator
twitter_generator = FewShotDatasetGenerator(
kind='twitter posts',
count=2,
user=UserProfile(
role="ML engineer",
intent="user is trying to promote Evidently AI opensource library for llm chatbot testing",
tone="confident"),
complexity="medium",
examples=[
"CI/CD is as crucial in AI systems as in traditional software. #mlops #cicd",
"Without test coverage for your data pipelines, you're flying blind.",
"Monitoring drift isn't a nice-to-have anymore. It's operational hygiene."
]
)This will generate the defined number of tweet-style posts that follow the tone and structure of the examples you provided.
While we're using social media posts here, the same approach works for any kind of inputs – from customer support questions to search queries or internal team messages.
RAG input-output generation
For RAG systems, you can use the generator to build a ground truth dataset by generating both the input (the query) and the expected output (the answer) from your own knowledge base.
It’s basically like running your RAG backwards: you start with an answer from the knowledge base, and then generate a realistic question someone might ask to get that answer. This gives you a reliable set of test queries and correct responses to evaluate your system against.
Let’s say you’re working on a customer support chatbot for a booking service. You can use the generator to create a bank of possible user questions with correct answers.
To start, you must prepare the knowledge base. For our example, we will use a toy hotel booking policy in a txt document.
Then, you can generate user queries. We will prompt the LLM to take on the persona of a new user and ask questions that relate to this booking process:
from evidently.llm.datagen import RagDatasetGenerator
from evidently.llm.rag.index import FileDataCollectionProvider
data = FileDataCollectionProvider(path="booking_kb.txt")
booking_rag = RagDatasetGenerator(
data,
count=2,
include_context=False,
user=UserProfile(intent="get to know system", role="new user"),
service="booking website",
)Once you hit run, the generator creates the dataset already split into columns – each question is paired with its correct answer right next to it. That’s your ground truth dataset, ready for testing!
Of course, it’s always worth reviewing the results, but checking the generated question-answer pairs is still much faster than writing everything from scratch.
Complex synthetic pipelines
The generator is fully adaptable, so it can be used as a building block in any complex synthetic pipeline.
For example, we can simulate a developer workflow and build a pipeline for generating code diffs and code reviews for those diffs. We will use the Evidently codebase as a knowledge source.
First, we’ll synthesize Git diffs:
import os
from evidently.llm.datagen import RagQueryDatasetGenerator, GenerationSpec
import evidently
data = FileDataCollectionProvider(path=os.path.dirname(evidently.__file__), recursive=True, pattern="*.py")
diff_generator = RagQueryDatasetGenerator(
data,
count=2,
chunks_per_query=1,
query_spec=GenerationSpec(kind="git diff"),
)
diff_generator.prepared_query_templateThen, we’ll pass the generated diffs into the generator to produce code review comments:
from evidently.llm.datagen import RagResponseDatasetGenerator
code_review_generator = RagResponseDatasetGenerator(
data,
query_spec=diff_generator.query_spec,
response_spec=GenerationSpec(kind="code review"),
queries=list(git_diffs["queries"]),
)
code_review_generator.prepared_response_templateThis lets you generate synthetic code reviews. For example, you can use them to create and tune LLM-based judges (or even LLM juries!) that evaluate the tone or quality of the review comments.
What’s next
The synthetic data generator is a flexible tool to quickly spin up custom pipelines, try out ideas, and build realistic test sets – especially when you don’t have real data yet, or need more edge cases.
With the current implementation, you can:
- Generate any test inputs, from search queries to code review comments.
- Customize generation style using user profiles (role, tone, intent, etc.).
- Generate input–output pairs and ground truth datasets for RAG evaluation.
- Simulate multi-step flows for more complex testing.
This is a Python-based workflow – fully open-source and great for integrating into development pipelines.
We also built a no-code version in Evidently Cloud. It's designed for product managers, analysts, or domain experts who want to set up and review generations directly in the UI. There, you can:
- Generate inputs and outputs using structured configuration in the UI.
- Review and edit generated content (drop, add, tweak rows).
- Store and organize your generated datasets.
Once you have the test data, you can also use it to run tests and build automated evaluators directly in the UI – no coding required.
Example generation flow. Set up your config: choose the generation type, define user profiles, and select the model.
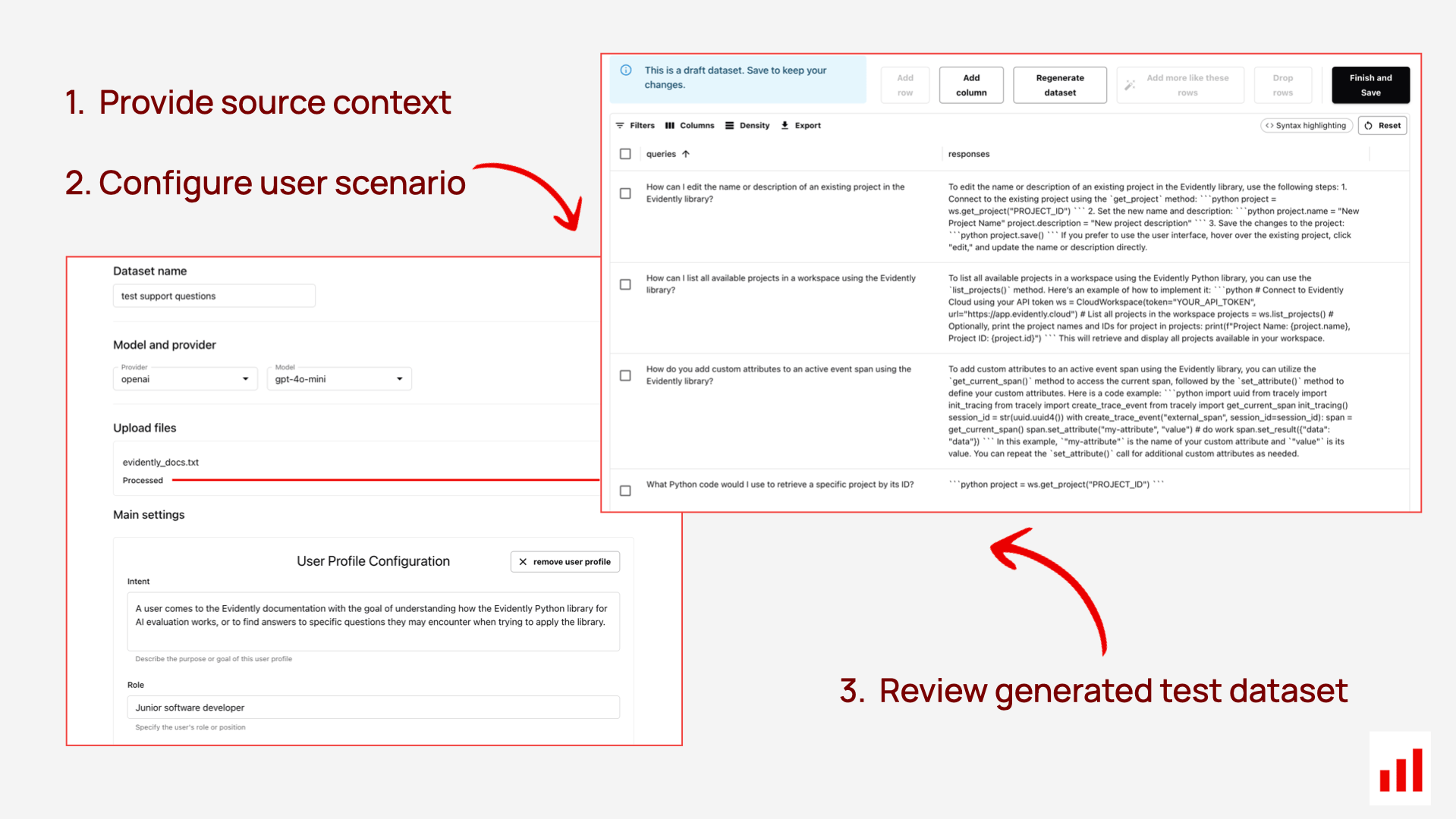
Example review flow. Easily browse and edit generated data – drop rows, add new ones, or tweak examples with just a few clicks.

Does this approach resonate with you? If you're working on LLM evaluation or testing and want to give the generator a try – come check it out and join the conversation on Discord. We'd love to hear how it works for your use case!


.svg)

You might also like


Get started with Evidently

