

-min.jpg)
contents
Agentic AI is quickly becoming one of the most discussed topics in tech, with some even calling 2025 the "year of AI agents." Over the past few years, these systems have evolved into sophisticated tools capable of handling complex, multi-step tasks with minimal human input.
As agents grow more intelligent and autonomous, the need to rigorously evaluate their capabilities – and uncover where they might fail – becomes critical. In this blog, we highlight 10 AI agent benchmarks designed to assess how well different LLMs perform as agents in real-world scenarios, tackling challenges like planning, decision-making, and tool use.
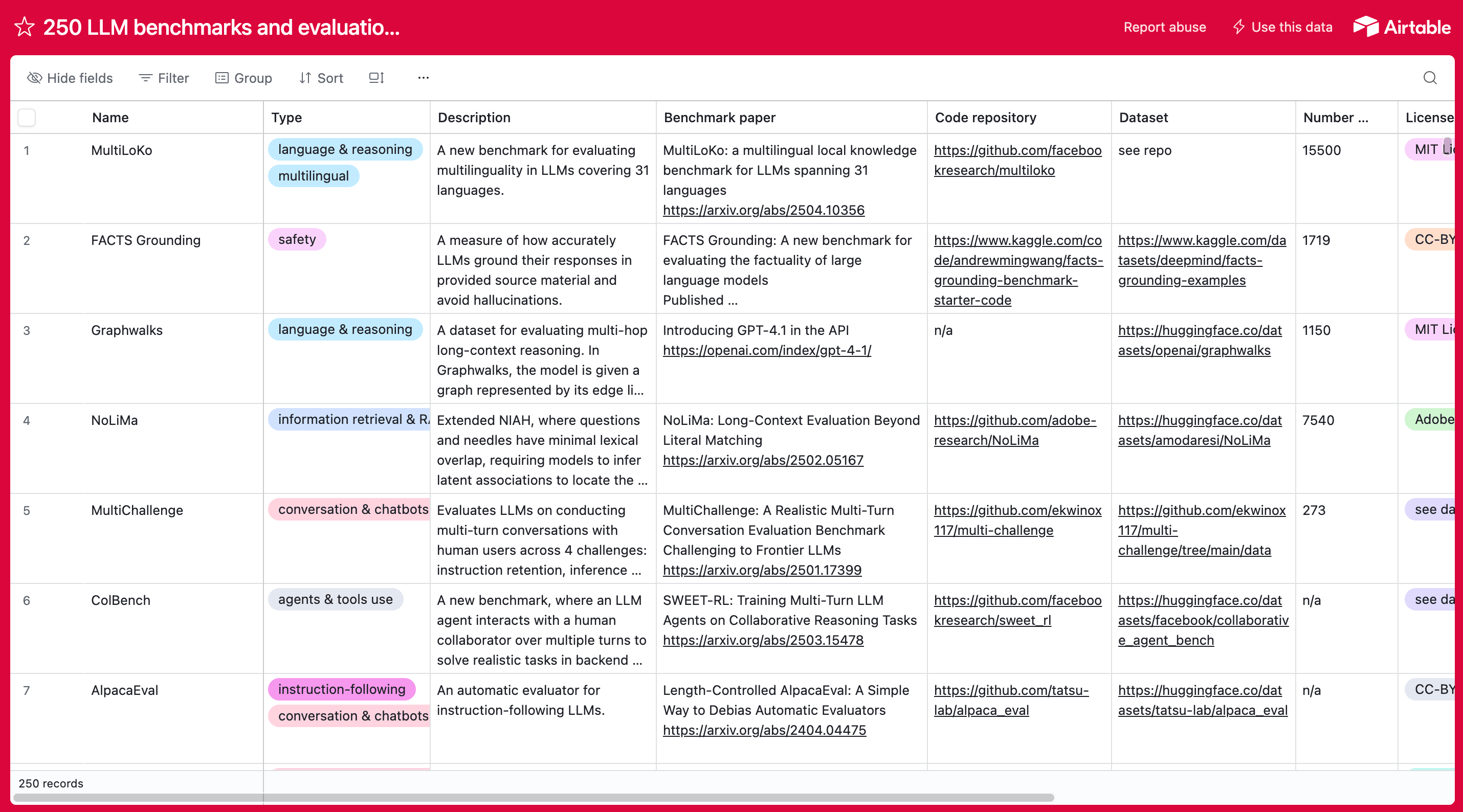
Want more examples of LLM benchmarks? We put together database of 250+ LLM benchmarks and datasets you can use to evaluate the performance of language models.
AgentBench
AgentBench assesses the ability of LLM-as-Agent to reason and make decisions in multi-turn open-ended settings. It evaluates agents across eight environments: Operating System, Database, Knowledge Graph, Digital Card Game, Lateral Thinking Puzzles, House-Holding, Web Shopping, and Web Browsing.
Datasets for all environments are practical multi-turn interacting challenges. The estimated solving turns for each problem range from 5 to 50.
Paper: AgentBench: Evaluating LLMs as Agents by Liu et al. (2023)
Dataset: AgentBench dataset

WebArena
WebArena is a benchmark and a self-hosted environment for autonomous agents performing web tasks. The environment simulates scenarios in four realistic domains: e-commerce, social forums, collaborative code development, and content management.
The benchmark evaluates functional correctness, where success means the agent achieves the final goal, independent of how it gets there. It encompasses 812 templated tasks and their variations, like browsing an e-commerce site, managing a forum, editing code repositories, and interacting with content management systems.
Paper: WebArena: A Realistic Web Environment for Building Autonomous Agents by Zhou et al. (2023)
Dataset: WebArena dataset

GAIA
GAIA is a benchmark for general AI assistants. It presents real-world questions requiring reasoning, multimodality handling, and tool-use proficiency. The dataset comprises 466 human-annotated tasks that mix text questions with attached context, e.g., images or files. The tasks cover various assistant use cases such as daily personal tasks, science, and general knowledge.
The questions can be sorted into three levels of increasing difficulty depending on the number of steps and tools required to solve the task. Level 1 questions generally require no tools and no more than 5 steps, while Level 3 questions require arbitrarily long sequences of actions and any number of tools.
Paper: GAIA: a benchmark for General AI Assistants by Mialon et al. (2023)
Dataset: GAIA dataset

MINT
MINT evaluates LLMs' ability to solve tasks with multi-turn interactions using tools and leveraging natural language feedback. Within this framework, LLMs access tools by executing Python code and receive users' feedback simulated by GPT-4.
The benchmark repurposes the instances of existing datasets to create a compact set of tasks requiring multiturn interaction. The MINT dataset includes three types of tasks: reasoning and question answering, code generation, and decision-making.
Paper: MINT: Evaluating LLMs in Multi-turn Interaction with Tools and Language Feedback by Wang et al. (2023)
Dataset: MINT dataset

ColBench
ColBench is a multi-turn benchmark that evaluates LLMs as collaborative agents working with simulated human partners. It focuses on backend coding and frontend design that require step-by-step collaboration: the model suggests code/design drafts, receives feedback, and refines iteratively – simulating a realistic development workflow.
The authors of the ColBench also propose a novel reinforcement learning (RL) algorithm – SWEET-RL – that significantly improves performance on the benchmark tasks. The algorithm trains a critic model that provides step-level rewards for improving the policy model.
Paper: SWEET-RL: Training Multi-Turn LLM Agents on Collaborative Reasoning Tasks by Zhou et al. (2025)
Dataset: ColBench dataset

ToolEmu
ToolEmu focuses on identifying risky behaviors of LLM agents when using tools. The benchmark contains 36 high-stakes tools and 144 test cases, covering scenarios where agent misuse could lead to serious consequences.
The framework simulates tool execution without actual tool infrastructure – this sandbox approach allows rapid and flexible prototyping. Alongside the emulator, the authors suggest an LM-based automatic safety evaluator that examines agent failures and quantifies associated risks.
Paper: Identifying the Risks of LM Agents with an LM-Emulated Sandbox by Ruan et al. (2023)
Dataset: ToolEmu dataset

Webshop
Webshop is a simulated e-commerce environment that evaluates LLM-powered agents on web-based shopping tasks. It simulates a realistic online store with 1.18 million products and 12,087 crowd-sourced instructions detailing what users want to buy – for example, “Find a budget-friendly red laptop with at least 16GB RAM.” Agents must navigate pages, search, filter, and complete purchases, mirroring realistic e-commerce interactions.
Paper: WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents by Yao et al. (2023)
Dataset: Webshop dataset

MetaTool
MetaTool is a benchmark designed to evaluate whether LLMs “know” when to use tools and can correctly choose the right tool from a set of options. Within the benchmark, authors also introduce a new evaluation dataset – ToolE. It contains over 21,000 prompts labeled with ground-truth tool assignments, including both single-tool and multi-tool scenarios.
The tasks cover both tool usage awareness and tool selection scenarios. Additionally, four subtasks are defined to evaluate different dimensions of tool selection: tool selection with similar choices, tool selection in specific scenarios, tool selection with possible reliability issues, and multi-tool selection.
Paper: MetaTool Benchmark for Large Language Models: Deciding Whether to Use Tools and Which to Use by Huang et al. (2023)
Dataset: MetaTool dataset

BFCL (Berkeley Function-Calling Leaderboard)
Berkeley Function-Calling Leaderboard evaluates the LLM's ability to call functions and tools. It tests how accurately models can generate valid function calls, including argument structure, API selection, and abstaining when appropriate.
The dataset comprises 2000 question-answer pairs in multiple languages – Python, Java, Javascript, and RestAPI – and diverse application domains. It supports multiple and parallel function calls and function relevance detection.
Paper: Berkeley Function-Calling Leaderboard by Yan et al. (2024)
Dataset: BFCL dataset

ToolLLM
ToolLLM is a framework for training and assessing LLMs on advanced API and tool usage. It tests models in real-world scenarios, focusing on retrieval, multi-step reasoning, correct invocation, and the ability to abstain.
The benchmark incorporates one of the largest open-source instruction datasets for API interaction – ToolBench. This massive dataset is built by extracting 16,464 RESTful APIs across 49 categories (e.g., weather, finance, social media) from RapidAPI, and then auto-generating user instructions with ChatGPT. It includes both single‑tool and multi‑tool scenarios.
The framework also offers an automatic evaluator backed up by ChatGPT to assess LLMs' tool-use capabilities. It comprises two key dimensions: LLMs' ability to successfully execute an instruction within limited budgets and the quality of solution paths.
Paper: ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs by Qin et al. (2023)
Dataset: ToolLLM dataset

Test your AI agent with Evidently
AI agent benchmarks are essential for comparing models, but your agent needs custom evaluations on your own data to test it during development and production.
That’s why we built Evidently. Our open-source library, with over 25 million downloads, makes it easy to test and evaluate LLM-powered applications, including AI agents.
We also provide Evidently Cloud, a no-code workspace for teams to collaborate on AI quality, testing, and monitoring and run complex evaluation workflows. You can generate synthetic data, create evaluation scenarios, run adversarial tests, and track performance – all in one place.
Ready to test your AI agent? Sign up for free or schedule a demo to see Evidently Cloud in action. We're here to help you build with confidence!


.svg)

You might also like


Get started with Evidently

