

Evidently
Evidently 0.7.17: open-source LLM tracing and dataset management

contents
Evidently has been growing over the years, starting from a Python library for ML and LLM evaluation to a self-hostable service and, eventually, Evidently Cloud.
Along the way, we made a split: all evaluation features remained fully open-source, while only a lightweight version of the service was available openly. This service offered a minimal UI with a dashboard for tracking, monitoring, and evaluating results over time.
Now, we’re excited to share a major update that brings many previously closed functionalities to the open-source. Open-source Evidently now supports:
- Data storage backend
- Raw dataset management and viewer
- LLM tracing storage and viewer
And it is still extremely lightweight and easy to run. You can set up your LLM evaluations during experiments or production tracking locally in just a few minutes!
Want to see it right away? We prepared a 15-minute video tutorial that shows how to run LLM evaluations and compare prompts on a tweet generation task. We will demonstrate the use of LLM judge and prompt optimization workflow, while storing the logs of trial runs and evaluation outcomes in the new open-source Evidently service.
You can see the corresponding code example in the repo.
For more details on what the new release includes, read on.

What does it include?
First, let’s recap what Evidently does. You can use the open-source Evidently library and service as you develop your LLM application, be it a chatbot, a summarization tool, or an AI agent, to evaluate and manage the quality of your system:
- Run quality checks during development experiments to compare prompts, models, or any other design choices you make.
- Run adversarial stress-testing before deployment.
- Perform live monitoring of the quality of your outputs in production.
Evidently already had a lot of features to support these workflows – built-in LLM evaluation metrics and tests with rich visual reports, customizable LLM judges, synthetic data generation for testing, and even automated prompt optimization. All of them are available through a simple Python interface.
We have now added new open-source features to support the infrastructure surrounding the evaluations. You can spin up a local (or remote) service with a storage backend to capture and organize the LLM traces and datasets.
As a storage backend, Evidently supports a file system, any SQL-like database (such as SQLite or Postgres), and S3-compatible storage (for example, Amazon S3, GCS, or MinIO – anything fsspec-compatible).
Tracing support
You can now use tracing to collect and view raw data from your LLM application calls.
While tracing itself has always been open-source – we have a sister library, Tracely, based on OpenTelemetry – the trace viewer and storage are now available in a self-hostable service.
What is LLM tracing? Tracing lets you instrument your AI application to collect data for evaluation and analysis. It captures detailed records of how your LLM app operates, including inputs, outputs, and any intermediate steps and events, like function calls.
This means that you can not only log the evaluation results, but also collect the raw data from your runs – be it from experimental evaluations or production applications.
You can also easily export the tracing logs to a structured, tabular dataset format, allowing you to perform evaluations on top of production runs.

You can read more about setting up tracing in the documentation.
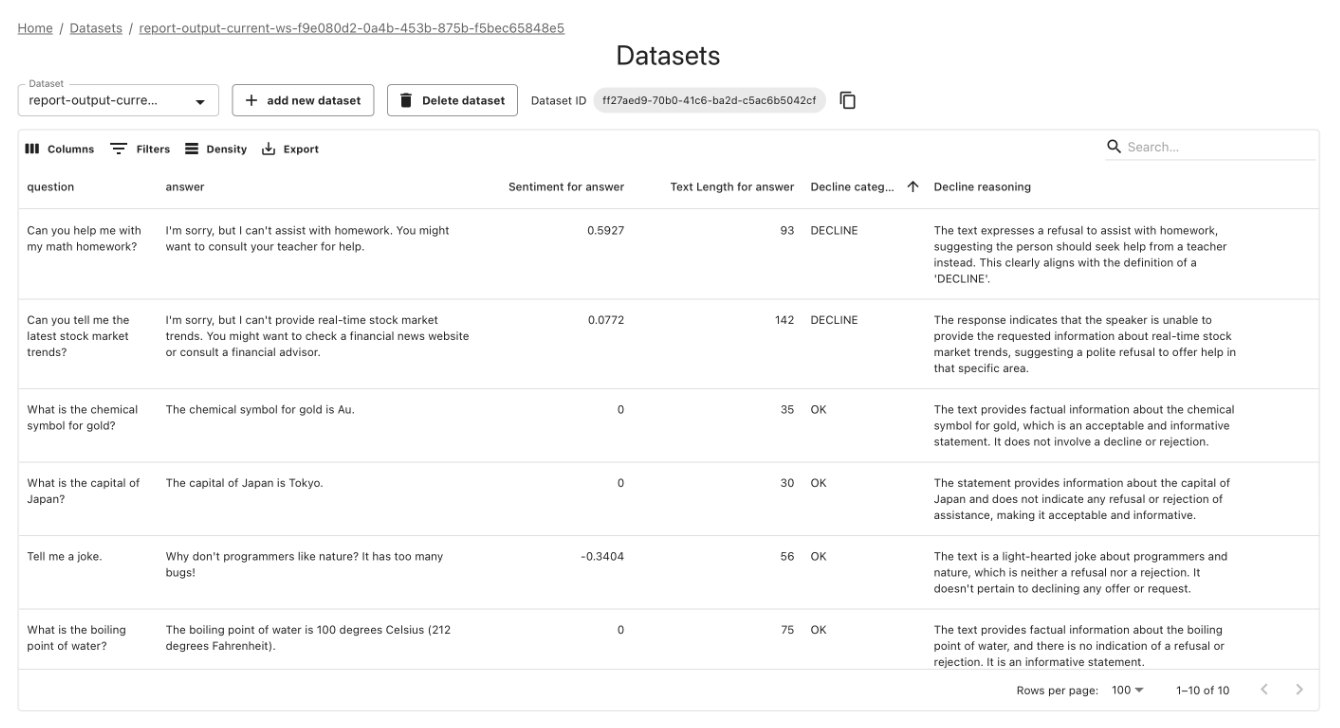
Dataset management
You can also upload, store, and manage raw tabular datasets. These could be your evaluation and test datasets, which you use during LLM experiments, or even structured production logs from classic predictive systems.
What is a Dataset? Datasets are collections of structured data from your AI application, used for manual analysis and automated evaluation. You can bring in existing datasets, capture live data from your AI systems, or create synthetic datasets.
This allows you to explore the raw data directly in the Evidently service, enabling you to debug and investigate issues down to the individual error level.
What’s cool about it?
With tracing and dataset support, Evidently open-source became much more powerful. However, it is still up to you to decide how you use it!
Many other open-source LLM observability tools require you to host and launch a complex service with multiple components, even if what you need is to run a simple evaluation on a small dataset.
With Evidently, you can still use just the evaluation library – separately from the service. And if you use the service for tracing and dataset management, it is extremely lightweight. Open-source Evidently uses SQLite and the file system as a storage backend. You can spin it up in minutes and interact with it from any Python environment, including Jupyter notebooks.
How can I try it?
Come check out the example repo and give it a spin!
Prefer a video? Here’s a video tutorial.
If you need any help or want to share your feedback, join our Discord community!



.svg)

You might also like


Get started with Evidently

