📚 LLM-as-a-Judge: a Complete Guide on Using LLMs for Evaluations. Get your copy
Product
LLM and AI Agents
Evaluate LLM quality and safety
Predictive ML Systems
Track data drift and predictive quality
GitHub
Docs
Resources
Blog
Insights on building AI products
LLM benchmarks
250 LLM benchmarks and datasets
Tutorials
AI observability and MLOps tutorials
ML and LLM system design
800 ML and LLM use cases
Guides
In-depth AI quality and MLOps guides
ML and AI platforms
45+ internal ML and AI platforms
Courses
Free LLM evals and AI observability courses
Community
Get support and chat about AI products
LLM evaluation for AI builders: applied course
Sign up now
GitHub
Contact us
GitHub
GitHub
All blogs about
#data-drift
LLM Evals
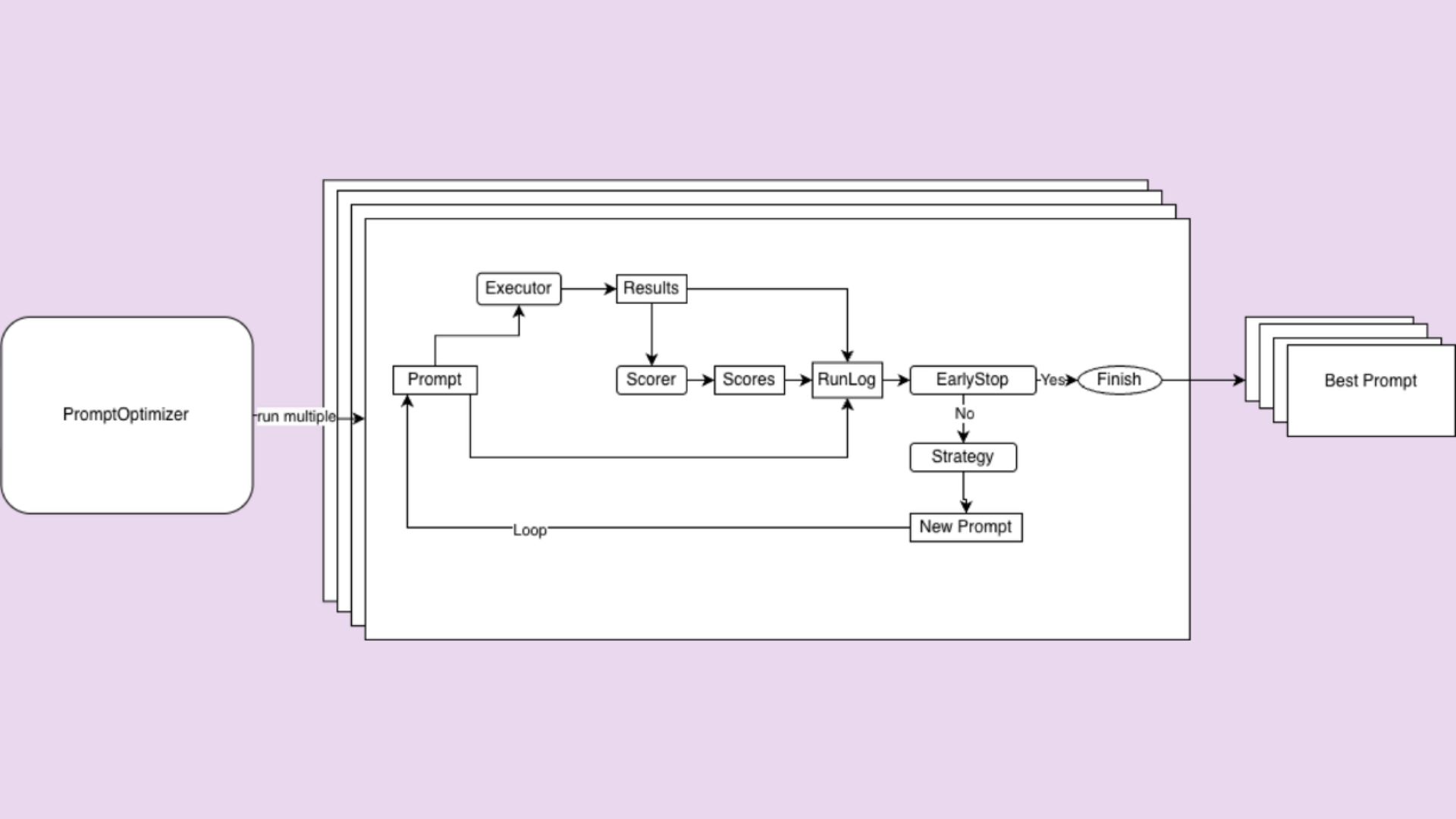
How we built open-source automated prompt optimization
In this blog, we explain common prompt optimization strategies and show how we designed and implemented automated prompt optimization in the open-source Evidently Python library.
Community
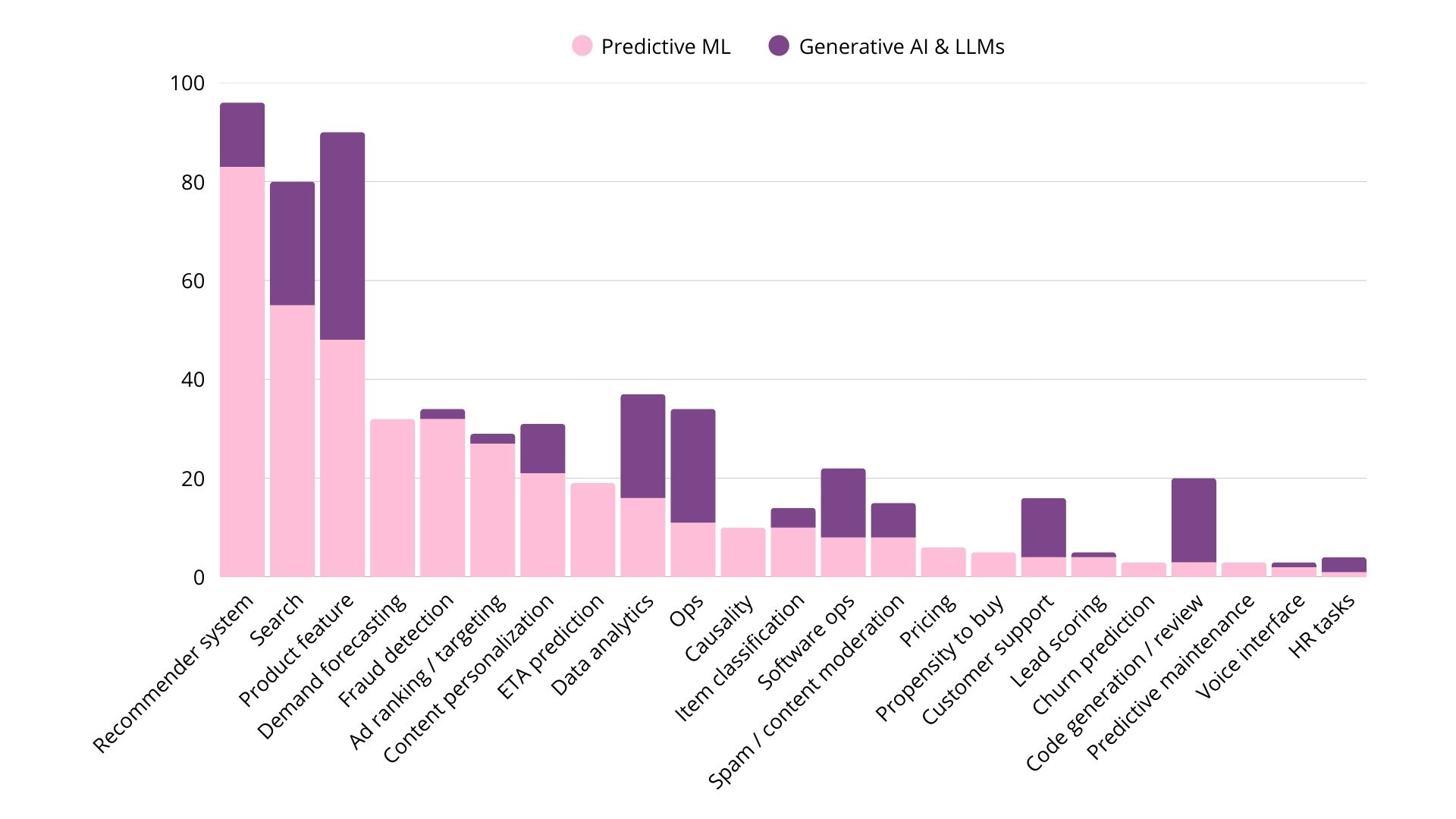
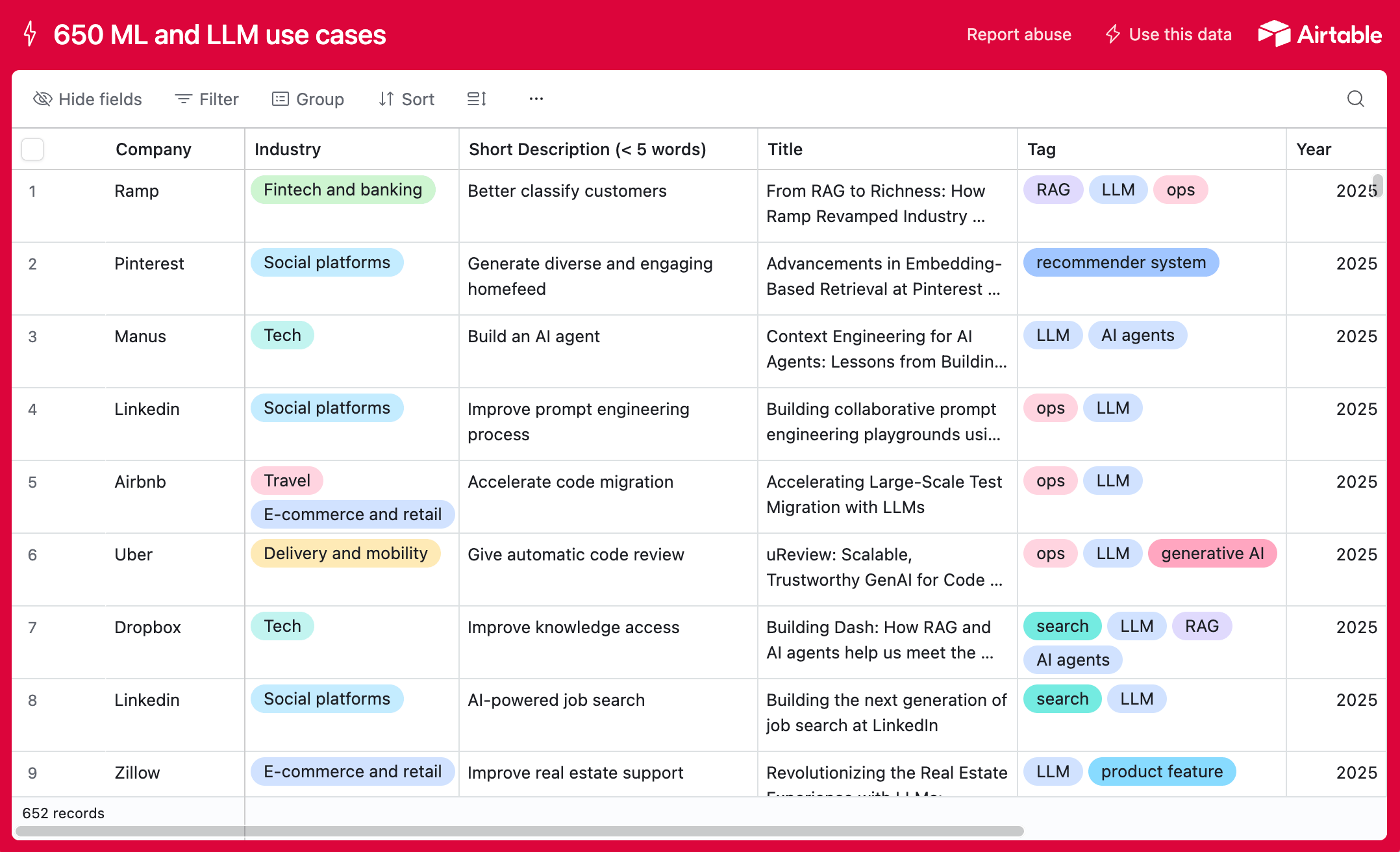
Learnings from 800+ GenAI and ML use cases
We collected and analyzed 800 real-world ML and GenAI use cases from 150+ companies. Here's what we've learned about how companies actually use AI in production and how it has evolved.
LLM Evals
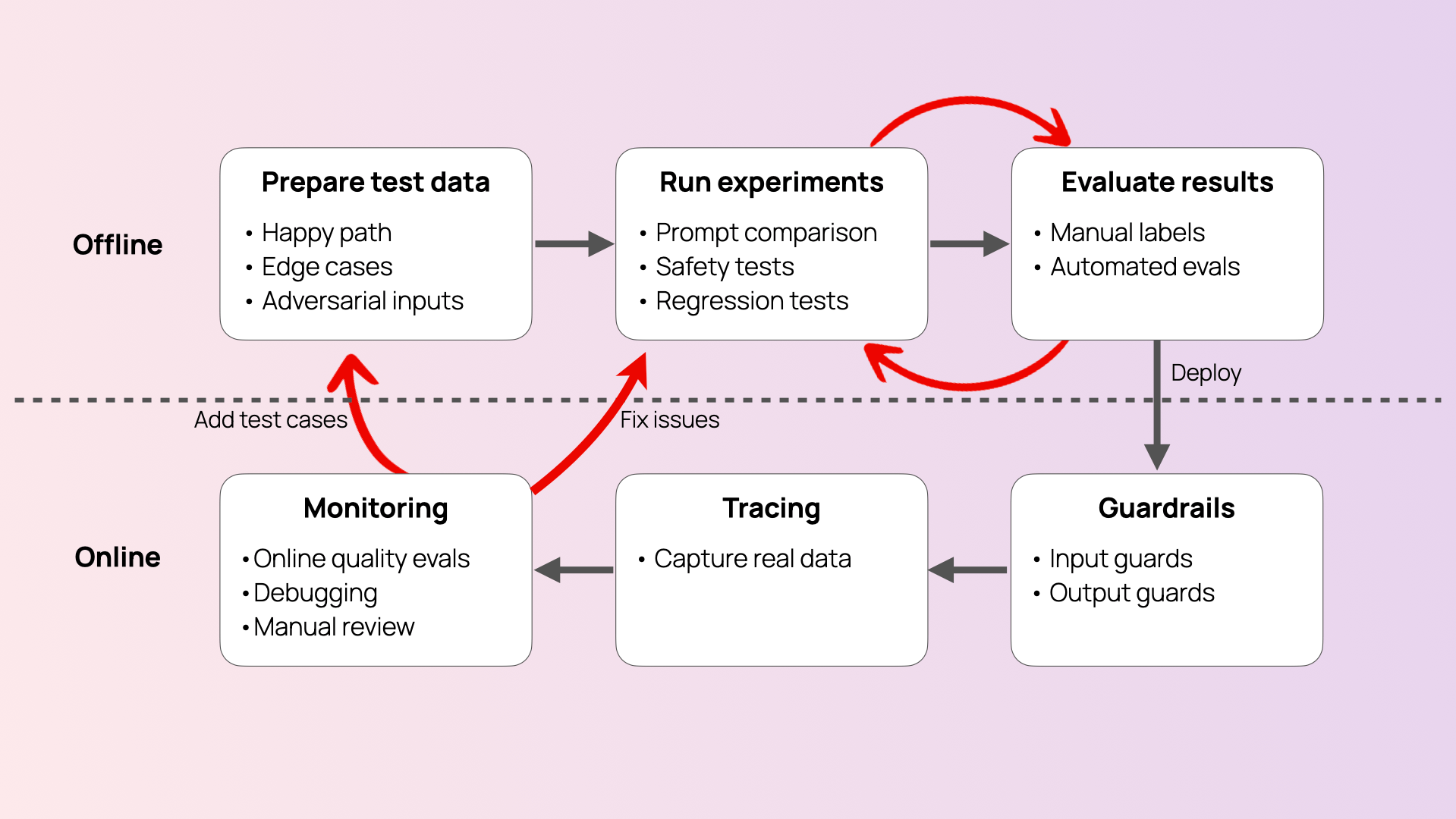
AI risk: 10 pitfalls to avoid when building AI products
In this blog, we break down ten common AI risks, share actionable ways to mitigate them, and outline a practical approach for building a continuous AI testing workflow.
Evidently
Evidently 0.7.17: open-source LLM tracing and dataset management
We released a major update that brings previously closed functionality to the open-source. Evidently Open-source now supports data storage backend, raw dataset management, LLM tracing storage and viewer.
LLM Evals
How to align LLM judge with human labels: a hands-on tutorial
In this tutorial, we will walk you through the process of designing and testing an LLM evaluator. We will also create an LLM judge that evaluates the quality of LLM-generated code reviews.
LLM Evals
F.A.Q on LLM judges: 7 questions we often get
LLM-as-a-judge is a popular approach to testing and evaluating AI systems. We answered some of the most common questions about how LLM judges work and how to use them effectively.
Community
7 agentic AI examples and use cases
In this blog, we will explore seven agentic AI examples and use cases in the real world — from transaction analysis to e-commerce recommendations to code review.
Community
25 AI benchmarks: examples of AI models evaluation
In this blog, we’ll explore AI benchmarks and why we need them. We’ll also provide 25 examples of widely used AI benchmarks for reasoning and language understanding, conversation abilities, coding, information retrieval, and tool use.
Community
8 AI hallucinations examples
AI hallucinations come in different forms: from giving factually incorrect responses to inventing nonexistent product features or even people. We compiled eight real-life AI hallucination examples.
Community
Gen AI use cases in 2025: learnings from 650+ real-world examples
Since 2023, we've been curating a database of real-world AI and ML use cases. Here is what we've learned from 650+ examples from top companies.
Community
10 AI agents examples from top companies
We compiled 10 real-world examples of companies using AI agents to transform their business operations: from financial data analysis to customer support to employee productivity.
LLM Evals
What is an LLM evaluation framework? Workflows and tools explained.
In this guide, we explain what it means to design an LLM evaluation framework for your AI application and introduce Evidently, an open-source LLM evaluation tool.
Evidently
Evidently 0.7.11: open-source synthetic data generation for LLM systems
If you’re building an AI system, you need solid test data. We made a synthetic data generator so you can create custom test datasets that mimic real-world data. Available in Evidently Open-source.
Evidently
10 AI agent benchmarks
We put together 10 AI agent benchmarks designed to assess how well different LLMs perform as agents in real-world scenarios, tackling challenges like planning, decision-making, and tool use.
Community
15 LLM coding benchmarks
This blog highlights 15 LLM coding benchmarks designed to evaluate and compare how different models perform on various coding tasks, including code completion, snippet generation, debugging, and more.
Evidently
Evidently 0.7.10: open-source prompt optimizer for LLM judges
Crafting a good prompt for an LLM judge isn’t trivial. We built a tool that automates LLM judge prompt generation based on expert-labeled datasets. Available in Evidently Open-source.
LLM Evals
Is this email okay? We asked a jury of LLM judges.
In this blog tutorial, we walk through the idea of LLM juries, the open-source implementation, and what we learned from LLM disagreements.
Evidently
CI/CD for LLM apps: Run tests with Evidently + GitHub actions
We released a GitHub Action that brings LLM output quality checks to your CI workflow and lets you auto-test your LLM system on every code update. Available in Evidently Open-source and Evidently Cloud.
LLM Evals
OWASP Top 10 LLM: How to test your Gen AI app in 2025
In this blog, we’ll walk you through the OWASP Top 10 LLM list of vulnerabilities for LLM applications, explore strategies to mitigate these risks, and show how to apply them to keep your AI product safe and reliable.
Community
Free LLM and Gen AI courses to take in 2025
Looking for free LLM and Gen AI courses to attend in 2025? We put together 10 online LLM and Gen AI courses that focus on the practical side of building with LLMs. They are free to join or publish their content for everyone to access without a fee.
Community
7 RAG benchmarks
We highlight seven RAG benchmarks that help measure and compare how well different LLMs handle core RAG challenges like large context windows, grounded reasoning, and using retrieved evidence effectively.
Community
How companies evaluate LLM systems: 7 examples from Asana, GitHub, and more
We put together 7 examples of how top companies like Asana and GitHub run LLM evaluations. They share how they approach the task, what methods and metrics they use, what they test for, and their learnings along the way.
Community
10 LLM safety and bias benchmarks
LLM safety benchmarks help to ensure models are robust and reliable. In this blog, we highlight 10 key safety and bias LLM benchmarks that help assess and improve LLM reliability.
Evidently
Evidently 0.6.3: Open-source RAG evaluation and testing
Evidently open-source now has more tools for evaluating RAG. You can score context relevance, evaluate generation quality, and use different LLMs as evaluators.
LLM Evals
10 RAG examples and use cases from real companies
RAG helps make LLM systems more accurate and reliable. We compiled 10 real-world examples of how companies use RAG to improve customer experience, automate routine tasks, and improve productivity.
Evidently
Upcoming Evidently API Changes
The Evidently API is evolving — and it’s getting better! We are updating the open-source Evidently API to make it simpler, more flexible, and easier to use. Explore the new features.
Community
AI regulations: EU AI Act, AI Bill of Rights, and more
In this guide, we’ll discuss key AI regulations, such as the EU AI Act and the Blueprint for AI Bill of Rights, and explain what they mean for teams building AI-powered products.
Community
LLM hallucinations and failures: lessons from 5 examples
Real-world examples of LLM hallucinations and other failures that can occur in LLM-powered products in the wild, such as prompt injection and out-of-scope usage scenarios.
Community
When AI goes wrong: 13 examples of AI mistakes and failures
From being biased to making things up, there are numerous instances where we’ve seen AI going wrong. In this post, we’ll explore thirteen notable AI failures when the technology didn’t perform as expected.
Tutorials
Wrong but useful: an LLM-as-a-judge tutorial
This tutorial shows how to create, tune, and use LLM judges. We'll make a toy dataset and assess correctness and verbosity. You can apply the same workflow for other criteria.
Evidently
Meet Evidently Cloud for AI Product Teams
We are launching Evidently Cloud, a collaborative AI observability platform built for teams developing products with LLMs. It includes tracing, datasets, evals, and a no-code workflow. Check it out!
Community
55 real-world LLM applications and use cases from top companies
How do companies use LLMs in production? We compiled 55 real-world LLM applications from companies that share their learnings from building LLM systems.
Tutorials
LLM regression testing workflow step by step: code tutorial
In this tutorial, we introduce the end-to-end workflow of LLM regression testing. You will learn how to run regression testing as a process and build a dashboard to monitor the test results.
Tutorials
Watch the language: A tutorial on regression testing for LLMs
In this tutorial, you will learn how to systematically check the quality of LLM outputs. You will work with issues like changes in answer content, length, or tone, and see which methods can detect them.
Community
MLOps Zoomcamp recap: how to monitor ML models in production?
Our CTO Emeli Dral was an instructor for the ML Monitoring module of MLOps Zoomcamp 2024, a free MLOps course. We summarized the ML monitoring course notes and linked to all the practical videos.
Community
AI, Machine Learning, and Data Science conferences to attend in 2025
We put together the most interesting conferences on AI, Machine Learning, and Data Science in 2025. And the best part? Some of them are free to attend or publish the content after the event.
Evidently
Evidently 0.4.25: An open-source tool to evaluate, test and monitor your LLM-powered apps
Evidently open-source Python library now supports evaluations for LLM-based applications, including RAGs and chatbots. You can compare, test, and monitor your LLM system quality from development to production.
Evidently
7 new features at Evidently: ranking metrics, data drift on Spark, and more
Did you miss some of the latest updates at Evidently open-source Python library? We summed up a few features we shipped recently in one blog.
Tutorials
Batch inference and ML monitoring with Evidently and Prefect
In this tutorial, you will learn how to run batch ML model inference and deploy a model monitoring dashboard for production ML models using open-source tools.
Community
MLOps courses to take in 2023
Looking for MLOps courses to attend in 2023? We put together five great online MLOps courses for data scientists and ML engineers. They are free to join or publish their content for everyone to access without a fee.
ML Monitoring
An MLOps story: how DeepL monitors ML models in production
How do different companies start and scale their MLOps practices? In this blog, we share a story of how DeepL monitors ML models in production using open-source tools.
Tutorials
How to stop worrying and start monitoring your ML models: a step-by-step guide
A beginner-friendly MLOps tutorial on how to evaluate ML data quality, data drift, model performance in production, and track them all over time using open-source tools.
Evidently
Evidently 0.4: an open-source ML monitoring dashboard to track all your models
Evidently 0.4 is here! Meet a new feature: Evidently user interface for ML monitoring. You can now track how your ML models perform over time and bring all your checks to one central dashboard.
Tutorials
Monitoring unstructured data for LLM and NLP with text descriptors
How do you monitor unstructured text data? In this code tutorial, we’ll explore how to track interpretable text descriptors that help assign specific properties to every text.
Tutorials
A simple way to create ML Model Cards in Python
In this code tutorial, you will learn how to create interactive visual ML model cards to document your models and data using Evidently, an open-source Python library.
Tutorials
ML serving and monitoring with FastAPI and Evidently
In this code tutorial, you will learn how to set up an ML monitoring system for models deployed with FastAPI. This is a complete deployment blueprint for ML serving and monitoring using open-source tools.
ML Monitoring
Shift happens: we compared 5 methods to detect drift in ML embeddings
Monitoring embedding drift is relevant for the production use of LLM and NLP models. We ran experiments to compare 5 drift detection methods. Here is what we found.
Community
AMA with Lina Weichbrodt: ML monitoring, LLMs, and freelance ML engineering
In this blog, we recap the Ask-Me-Anything session with Lina Weichbrodt. We chatted about ML monitoring and debugging, adopting LLMs, and the challenges of being a freelance ML engineer.
Tutorials
Batch ML monitoring blueprint: Evidently, Prefect, PostgreSQL, and Grafana
In this code tutorial, you will learn how to run batch ML model inference, collect data and ML model quality monitoring metrics, and visualize them on a live dashboard.
Tutorials
How to set up ML monitoring with email alerts using Evidently and AWS SES
In this tutorial, you will learn how to implement Evidently checks as part of an ML pipeline and send email notifications based on a defined condition.
ML Monitoring
An MLOps story: how Wayflyer creates ML model cards
How do different companies start and scale their MLOps practices? In this blog, we share a story of how Wayflyer creates ML model cards using open-source tools.
Tutorials
A tutorial on building ML and data monitoring dashboards with Evidently and Streamlit
In this tutorial, you will learn how to create a data quality and ML model monitoring dashboard using the two open-source libraries: Evidently and Streamlit.
Community
AMA with Stefan Krawczyk: from building ML platforms at Stitch Fix to an open-source startup on top of the Hamilton framework
In this blog, we recap the Ask-Me-Anything session with Stefan Krawczyk. We chatted about how to build an ML platform and what data science teams do wrong about ML dataflows.
ML Monitoring
How to build an ML platform? Lessons from 10 tech companies
How to approach building an internal ML platform if you’re not Google? We put together stories from 10 companies that shared their platforms’ design and learnings along the way.
Tutorials
Monitoring NLP models in production: a tutorial on detecting drift in text data
In this tutorial, we will explore issues affecting the performance of NLP models in production, imitate them on an example toy dataset, and show how to monitor and debug them.
Community
AMA with Neal Lathia: data science career tracks, shipping ML models to production, and Monzo ML stack
In this blog, we recap the Ask-Me-Anything session with Neal Lathia. We chatted about career paths of an ML Engineer, building and expanding ML teams, Monzo’s ML stack, and 2023 ML trends.
Evidently
Evidently 0.2.2: Data quality monitoring and drift detection for text data
Meet the new feature: data quality monitoring and drift detection for text data! You can now use the Evidently open-source Python library to evaluate, test, and monitor text data.
Community
50 best machine learning blogs from engineering teams
Want to know how companies with top engineering teams do machine learning? We put together a list of the best machine learning blogs from companies that share specific ML use cases, lessons learned from building ML platforms, and insights into the tech they use.
Community
AMA with Ben Wilson: planning ML projects, AutoML, and deploying at scale
In this blog, we recap the Ask-Me-Anything session with Ben Wilson. We chatted about AutoML use cases, deploying ML models to production, and how one can learn about ML engineering.
Evidently
Meet Evidently 0.2, the open-source ML monitoring tool to continuously check on your models and data
We are thrilled to announce our latest and largest release: Evidently 0.2. In this blog, we give an overview of what Evidently is now.
Evidently
Evidently feature spotlight: NoTargetPerformance test preset
In this series of blogs, we are showcasing specific features of the Evidently open-source ML monitoring library. Meet NoTargetPerformance test preset!
Community
AMA with Rick Lamers: the evolution of data orchestration tools and the perks of open source
In this blog, we recap the Ask-Me-Anything session with Rick Lamers, where we chatted about the evolution of orchestration tools, their place within the MLOps landscape, the future of data pipelines, and building an open-source project amidst the economic crisis.
Community
How to contribute to open source as a Data Scientist, and Hacktoberfest 2022 recap
Now that Hacktoberfest 2022 is over, it’s time to celebrate our contributors, look back at what we’ve achieved together, and share what we’ve learned during this month of giving back to the community through contributing to open source.
Evidently
Evidently 0.1.59: Migrating from Dashboards and JSON profiles to Reports
In Evidently v0.1.59, we moved the existing dashboard functionality to the new API. Here is a quick guide on migrating from the old to the new API. In short, it is very, very easy.
ML Monitoring
ML model maintenance. “Should I throw away the drifting features”?
Imagine you have a machine learning model in production, and some features are very volatile. Their distributions are not stable. What should you do with those? Should you just throw them away?
Community
AMA with Jacopo Tagliabue: reasonable scale ML, testing recommendation systems, and hot DataOps
In this blog, we recap the Ask-Me-Anything session with Jacopo Tagliabue, where we chatted about ML at a reasonable scale, testing RecSys, MLOps anti-patterns, what’s hot in DataOps, fundamentals in MLOps, and more.
Community
AMA with Bo Yu and Sean Sheng: why ML deployment is hard
In this blog, we recap the Ask-Me-Anything session with Bozhao Yu and Sean Sheng, where we chatted about why deploying a model is hard, beginner mistakes and how to avoid them, the challenges of building an open-source product, and BentoML’s roadmap.
ML Monitoring
Pragmatic ML monitoring for your first model. How to prioritize metrics?
There is an overwhelming set of potential metrics to monitor. In this blog, we'll try to introduce a reasonable hierarchy.
Community
AMA with Doris Xin: AutoML, modern data stack, and reunifying the tools
In this blog, we recap Ask-Me-Anything session with Doris Xin, that covered the roles of Data Scientists and Data Engineers in an ML cycle, automation, MLOps tooling, bridging the gap between development and production, and more.
Community
AMA with Fabiana Clemente: synthetic data, data-centric approach, and rookie mistakes to avoid
We recap Ask-Me-Anything session with Fabiana Clemente, which covered synthetic data, its quality, beginner mistakes in data generation, the data-centric approach, and how well companies are doing in getting there.
ML Monitoring
Monitoring ML systems in production. Which metrics should you track?
When one mentions "ML monitoring," this can mean many things. Are you tracking service latency? Model accuracy? Data quality? This blog organizes everything one can look at in a single framework.
Evidently
Evidently 0.1.52: Test-based ML monitoring with smart defaults
Meet the new feature in the Evidently open-source Python library! You can easily integrate data and model checks into your ML pipeline with a clear success/fail result. It comes with presets and defaults to make the configuration painless.
ML Monitoring
Which test is the best? We compared 5 methods to detect data drift on large datasets
We ran an experiment to help build an intuition on how popular drift detection methods behave. In this blog, we share the key takeaways and the code to run the tests on your data.
Community
AMA with Matt Squire: what makes a good open-source tool great, and the future of MLOps
In this blog we recap Ask-Me-Anything session with Matt Squire, that covered MLOps maturity and future, how MLOps fits in data-centric AI, and why open-source wins.
Tutorials
How to set up ML Monitoring with Evidently. A tutorial from CS 329S: Machine Learning Systems Design.
Our CTO Emeli Dral gave a tutorial on how to use Evidently at the Stanford Winter 2022 course CS 329S on Machine Learning System design. Here is the written version of the tutorial and a code example.
Community
AMA with Hamza Tahir: MLOps trends, tools, and building an open-source startup
In this blog we recap Ask-Me-Anything session with Hamza Tahir, that covered MLOps trends and tools, the future of real-time ML, and building an open-source startup.
Community
Evidently Community Call #2 Recap: custom text comments, color schemes and a library of statistical tests
In this blog we recap the second Evidently Community Call that covers the recent feature updates in our open-source ML monitoring tool.
Community
AMA with Alexey Grigorev: MLOps tools, best practices for ML projects, and tips for community builders
In this blog we recap Ask-Me-Anything session with Alexey Grigorev, that covered all things production machine learning, from tools to workflow, and even a bit on community building.
ML Monitoring
Q&A: ML drift that matters. "How to interpret data and prediction drift together?"
Data and prediction drift often need contextual interpretation. In this blog, we walk you through possible scenarios for when you detect these types of drift together or independently.
Evidently
Evidently 0.1.46: Evaluating and monitoring data quality for ML models.
Meet the new Data Quality report in the Evidently open-source Python library! You can use it to explore your dataset and track feature statistics and behavior changes.
Evidently
7 highlights of 2021: A year in review for Evidently AI
We are building an open-source tool to evaluate, monitor, and debug machine learning models in production. Here is a look back at what has happened at Evidently AI in 2021.
Evidently
Evidently 0.1.35: Customize it! Choose the statistical tests, metrics, and plots to evaluate data drift and ML performance.
Now, you can easily customize the pre-built Evidently reports to add your metrics, statistical tests or change the look of the dashboards with a bit of Python code.
ML Monitoring
Q&A: Do I need to monitor data drift if I can measure the ML model quality?
Even if you can calculate the model quality metric, monitoring data and prediction drift can be often useful. Let’s consider a few examples when it makes sense to track the distributions of the model inputs and outputs.
ML Monitoring
"My data drifted. What's next?" How to handle ML model drift in production.
What can you do once you detect data drift for a production ML model? Here is an introductory overview of the possible steps.
Evidently
Evidently 0.1.30: Data drift and model performance evaluation in Google Colab, Kaggle Kernel, and Deepnote
Now, you can use Evidently to display dashboards not only in Jupyter notebook but also in Colab, Kaggle, and Deepnote.
ML Monitoring
Q&A: What is the difference between outlier detection and data drift detection?
When monitoring ML models in production, we can apply different techniques. Data drift and outlier detection are among those. What is the difference? Here is a visual explanation.
Evidently
Real-time ML monitoring: building live dashboards with Evidently and Grafana
You can use Evidently together with Prometheus and Grafana to set up live monitoring dashboards. We created an integration example for Data Drift monitoring. You can easily configure it to use with your existing ML service.
Tutorials
How to detect, evaluate and visualize historical drifts in the data
You can look at historical drift in data to understand how your data changes and choose the monitoring thresholds. Here is an example with Evidently, Plotly, Mlflow, and some Python code.
ML Monitoring
To retrain, or not to retrain? Let's get analytical about ML model updates
Is it time to retrain your machine learning model? Even though data science is all about… data, the answer to this question is surprisingly often based on a gut feeling. Can we do better?
Evidently
Evidently 0.1.17: Meet JSON Profiles, an easy way to integrate Evidently in your prediction pipelines
Now, you can use Evidently to generate JSON profiles. It makes it easy to send metrics and test results elsewhere.
ML Monitoring
Can you build a machine learning model to monitor another model?
Can you train a machine learning model to predict your model’s mistakes? Nothing stops you from trying. But chances are, you are better off without it.
Tutorials
What Is Your Model Hiding? A Tutorial on Evaluating ML Models
There is more to performance than accuracy. In this tutorial, we explore how to evaluate the behavior of a classification model before production use.
Evidently
Evidently 0.1.8: Machine Learning Performance Reports for Classification Models
You can now use Evidently to analyze the performance of classification models in production and explore the errors they make.
Tutorials
How to break a model in 20 days. A tutorial on production model analytics
What can go wrong with ML model in production? Here is a story of how we trained a model, simulated deployment, and analyzed its gradual decay.
Evidently
Evidently 0.1.6: How To Analyze The Performance of Regression Models in Production?
You can now use Evidently to analyze the performance of production ML models and explore their weak spots.
Evidently
Evidently 0.1.4: Analyze Target and Prediction Drift in Machine Learning Models
Our second report is released! Now, you can use Evidently to explore the changes in your target function and model predictions.
Evidently
Introducing Evidently 0.0.1 Release: Open-Source Tool To Analyze Data Drift
We are excited to announce our first release. You can now use Evidently open-source python package to estimate and explore data drift for machine learning models.
ML Monitoring
Machine Learning Monitoring, Part 5: Why You Should Care About Data and Concept Drift
No model lasts forever. While the data quality can be fine, the model itself can start degrading. A few terms are used in this context. Let’s dive in.
ML Monitoring
Machine Learning Monitoring, Part 4: How To Track Data Quality and Data Integrity
A bunch of things can go wrong with the data that goes into a machine learning model. Our goal is to catch them on time.
ML Monitoring
Machine Learning Monitoring, Part 3: What Can Go Wrong With Your Data?
Garbage in is garbage out. Input data is a crucial component of a machine learning system. Whether or not you have immediate feedback, your monitoring starts here.
Product
LLM and AI Agents
Evaluate LLM quality and safety
Predictive ML Systems
Track data drift and predictive quality
GitHub
Docs
Resources
Blog
Insights on building AI products
LLM benchmarks
250 LLM benchmarks and datasets
Tutorials
AI observability and MLOps tutorials
ML and LLM system design
800 ML and LLM use cases
Guides
In-depth AI quality and MLOps guides
ML and AI platforms
45+ internal ML and AI platforms
Community
Get support and chat about AI products
Courses
Free LLM evals and AI observability courses
LLM evaluations for AI builders: applied course
Sign up now
Contact us
GitHub
GitHub
GitHub
Get started with Evidently
Open-source AI evaluation and observability for your systems.
GitHub
Explore docs
By clicking “Accept”, you agree to the storing of cookies on your device to enhance site navigation, analyze site usage, and assist in our marketing efforts. View our
Privacy Policy
for more information.
Deny
Accept
Privacy Preferences
Essential cookies
Required
Marketing cookies
Essential
Personalization cookies
Essential
Analytics cookies
Essential
Reject all cookies
Allow all cookies
Save preferences







-min.jpg)





-min.jpg)





-min.jpg)


-min.jpg)



%20(1).jpg)
.jpg)






















.png)


.png)













































